Graph Automation
Automate your data pipeline and build knowledge graphs effortlessly.
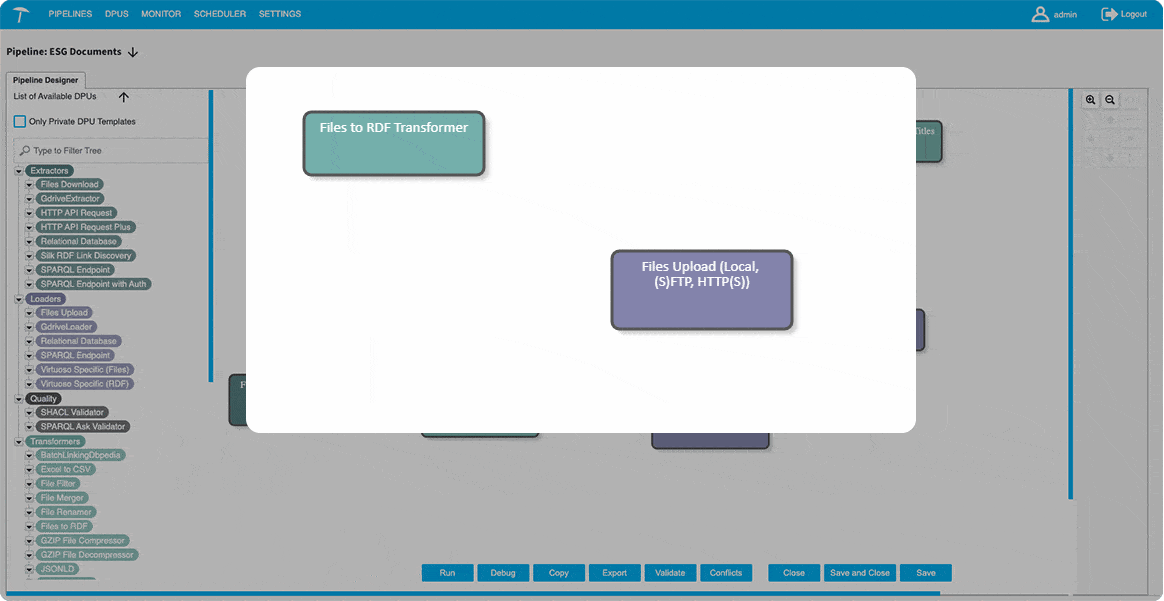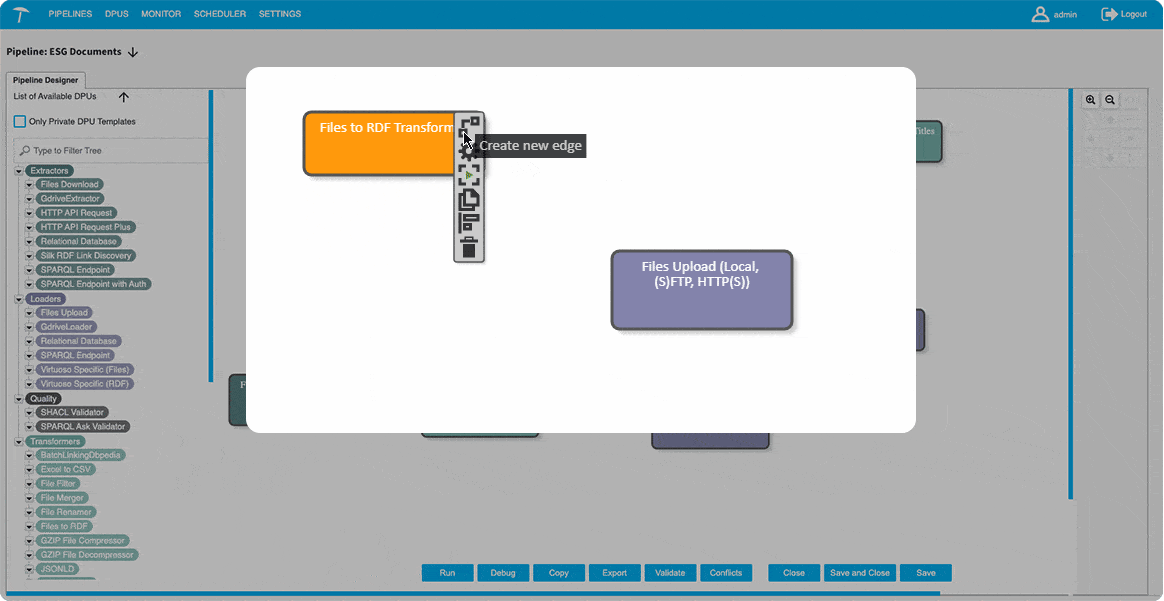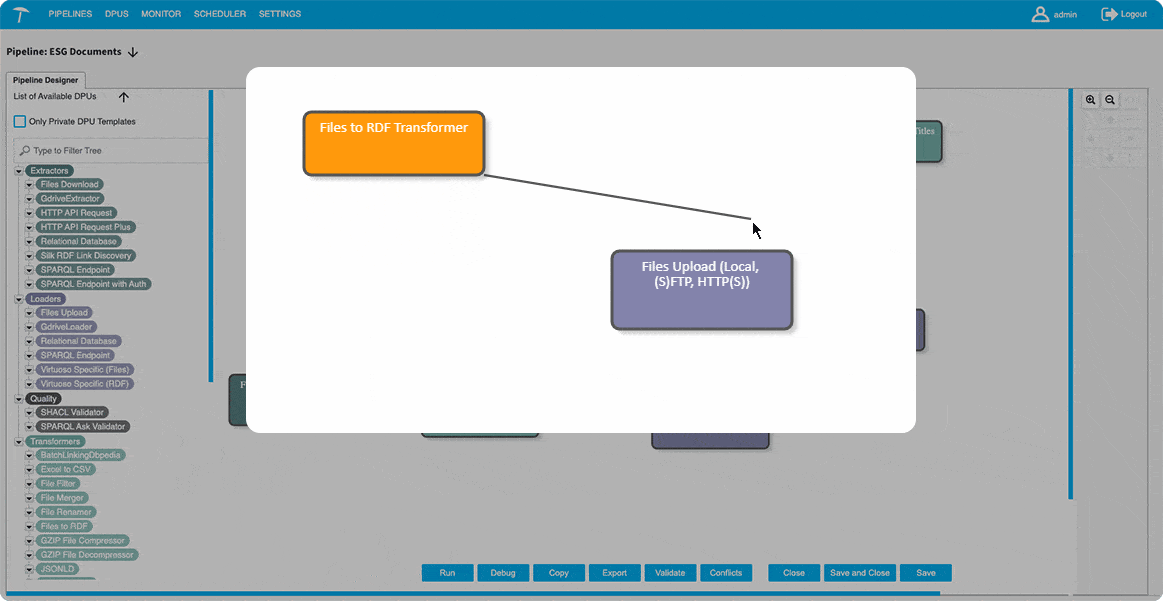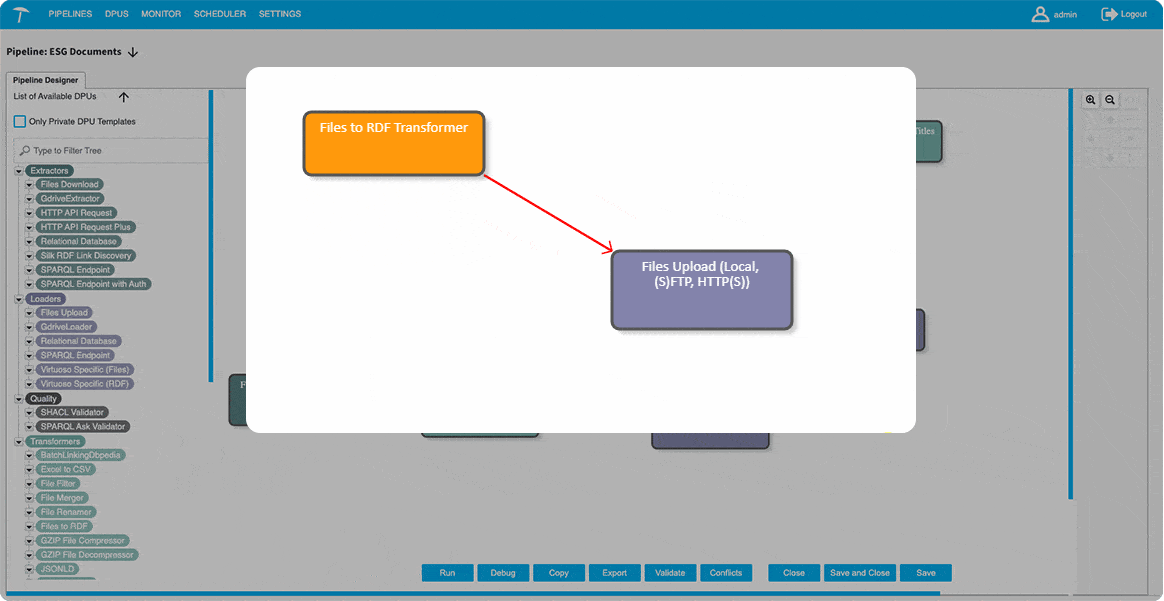

Graphwise Graph Automation is an intelligent ETL (Extract, Transform, Load) engine built specifically for semantic data—automating how enterprises ingest, clean, and convert scattered information into unified knowledge graphs.
Traditional data preparation creates a costly IT bottleneck; connecting new data sources typically requires complex coding, leaving business teams waiting weeks for critical insights.
Graphwise eliminates this friction by replacing tedious manual engineering with automated, visual pipelines, enabling your team to effortlessly unify any data format for instant enterprise AI readiness through an intuitive drag-and-drop workspace.
Ingest and transform any data source.
Graphwise Graph Automation seamlessly ingests structured, semi-structured, and unstructured data to unify it into a single, standardized format that can be processed by search engines for end-user applications.
- Load the data from any source (CSV, XML, text documents, tables, relational databases, and JSON)
- Transform the data into RDF to enable the creation of semantic-based knowledge models
- Instantly run quality checks, adjust file structures, rename identifiers, and eliminate duplicate records during ingestion
- Create additional transformations such as entity linking, schema mapping, and data validation
- Automatically catch and resolve graph errors using advanced validation queries to ensure a flawless data repository


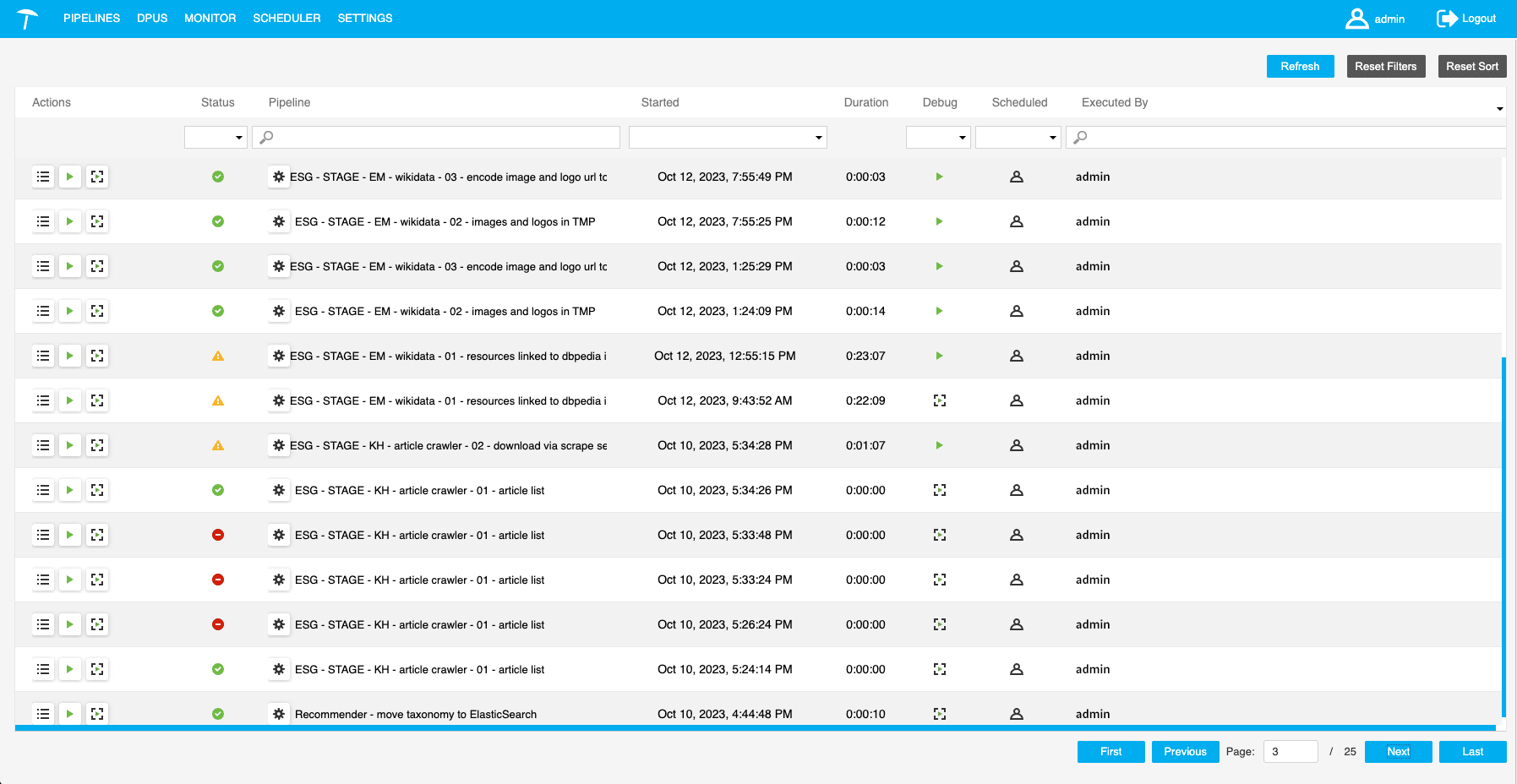
Design complex data flows natively and visually.
Building data pipelines shouldn’t require an advanced IT degree. Graphwise offers an intuitive graphical workspace that simplifies pipeline creation, execution, and monitoring.
- Rely on drag-and-drop building blocks and pre-defined templates: Loaders (e.g. uploading files), Transformers (e.g. files to RDF), and Extractors (e.g. SPARQL endpoint)
- Draw data paths and instantly connect your pipeline to external APIs, databases, or servers
- Define granular user permissions to easily manage which data pipelines are private, read-only, or public across your team
- Monitor the progress of a pipeline in an interface that indicates if it has been started, scheduled, debugged, executed, and more
- Use extensive debugging tools to investigate/improve data at any point of the pipeline
Eliminate tedious data preparation.
Enterprise data grows too fast for manual curation. Graphwise Graph Automation applies structured metadata to your content at scale, ensuring your data is automatically primed for downstream AI applications like Semantic Search, GraphRAG, and knowledge hubs.

“In our organization and with our resourcing, we can’t expect to have someone with IT capabilities or a developer skill set to set up a pipeline every time, so we are happy to have simple mapping for our pipelines so that anyone can do the task.”
Les Kneebone
Information Architect / Digital Librarian, CEBRA
Explore Our Success Stories
Expanding Editorial Output for the FIFA World Cup, Delivering 800+ Pages in Weeks
The BBC used semantic technology to To power its 2010 FIFA World Cup website to cut editorial costs and improve user experience.
Read more
Scaling Search and Content Governance with Semantic Technology
Microsoft Docs transformed millions of technical documents into a semantically enriched, scalable knowledge system.
Read moreTransforming AI Reliability by Building Knowledge Graph-Powered Customer Support
Avalara used GraphRAG to establish a foundation for reliable, mission-critical AI applications in tax and financial services.
Read more
Building a Collaborative Knowledge Hub for AI-Powered Predictive Intelligence
Sensing Clues implemented Graphwise’s Knowledge Management Suite to build vast organizational knowledge models.
Read moreTake a deep dive with an expert.
Please fill out the form to get connected with a Graphwise Team Member. Get ready for your guided walkthrough and full-access account!