GraphRAG
Eliminate LLM hallucinations and ensure GenAI applications deliver reliable, audit-ready responses
While LLMs offer a massive competitive advantage, they are inherently domain-agnostic and “frozen” in their training state. For enterprises, this creates a dangerous “Hallucination Gap” where the AI generates confident but factually incorrect or nonsensical answers.
To turn AI into a reliable business tool, you must ground it in your proprietary, real-time data. This is the goal of GraphRAG.
What is RAG?
Retrieval Augmented Generation (RAG) is a framework designed to make LLMs more reliable by feeding them relevant, up-to-date knowledge extracted directly from a company’s document ecosystem. This context accompanies the user’s question, ensuring the AI bases its response on specific enterprise facts rather than generic training data.
However, conventional RAG has a significant limitation: it treats your data as a flat list of text chunks. It can find similar words, but it cannot understand the complex relationships, hierarchies, or logic that connect your business information.
What is GraphRAG?
GraphRAG (Graph-enhanced RAG) replaces the flat, “vector-only” approach with an an advanced architecture that uses a Knowledge Graph to provide a “context-infused” retrieval layer.
By mapping your data into a network of entities and relationships, GraphRAG allows the LLM to navigate your enterprise knowledge like an expert, not a keyword search engine.

Relational Intelligence
Instead of treating data as isolated “chunks,” GraphRAG understands hierarchies and dependencies, following your business logic
By 2027, more than 40% of digital workplace operational activities will be performed using management tools that are enhanced by GenAI, dramatically reducing the labor required.
Predicts for Generative AI
Cameron Haight, Chris Matchett, 2024
Overcome the Limits of Large Language Models
While hallucinations can never be completely ruled out, a GraphRAG methodology replaces AI “guessing” with verifiable, graph-based grounding.
| Type of Hallucination | Conventional LLM Limitations | How GraphRAG Mitigates |
|---|---|---|
|
Nonsensical or Out-of-Context Output |
LLMs struggle with ambiguous terms and fail to distinguish context, leading them down the wrong path. |
GraphRAG injects the precise meaning and taxonomy of words into the query before it reaches the LLM. |
|
Factual Contradictions |
When an LLM hits proprietary data gaps or outdated training data, it fills those blanks with fictional facts. |
The rich, domain-specific context from the Knowledge Graph fills the data gaps with verifiable facts. |
|
Prompt and Policy Contradictions |
Strict, baked-in provider safety rules can cause the LLM to decouple from a prompt, returning useless answers. |
GraphRAG structures the prompt dynamically to align with complex enterprise workflows and model constraints. |
Unlocking the Business Potential: KPIs and ROI
The biggest drain on enterprise productivity is the friction of finding and synthesizing information scattered across disparate corporate systems. A GraphRAG framework solves this by connecting your data into a coherent network of knowledge, delivering immediate, measurable returns on efficiency and cost savings.
Higher Operational Efficiency
A typical knowledge worker spends nearly 30% of their day searching for and processing information. Instead of returning long lists of flat documents, a GraphRAG approach connects the dots across disconnected silos to deliver instant, summarized answers.
Outcome: An increase in operational efficiency of 15-20%.



Faster Onboarding and Democratic Access
To get accurate results from standard AI search, employees usually need deep domain expertise (specific jargon and terminology). A GraphRAG architecture bypasses this barrier by mapping out business logic, relationships, and synonyms automatically.
Outcome: Non-technical or newly onboarded employees can query complex enterprise data accurately from day 1.
Lower Maintenance Costs
Instead of relying on expensive, continuous LLM fine-tuning and massive compute power to improve accuracy, GraphRAG solves the problem at the context layer.
Outcome: Combining prompt engineering with GraphRAG cuts implementation and maintenance costs by 70%, creating an ROI increase of 3x or higher.
Graphwise Enterprise-Ready Workflow Engine
While building a successful RAG prototype in an experimental setting is relatively straightforward, these solutions frequently fail to scale because they lack the governance, data privacy controls, and observability required by modern business operations.
To bridge this gap, Graphwise GraphRAG provides the first production-ready “Trust Layer” needed to build, scale, and monitor advanced AI workflows with zero friction.
Useful Resources

Graphwise GraphRAG
Scale your enterprise intelligence with a GraphRAG solution from Graphwise. Move from concept to production in days, not months.
Read more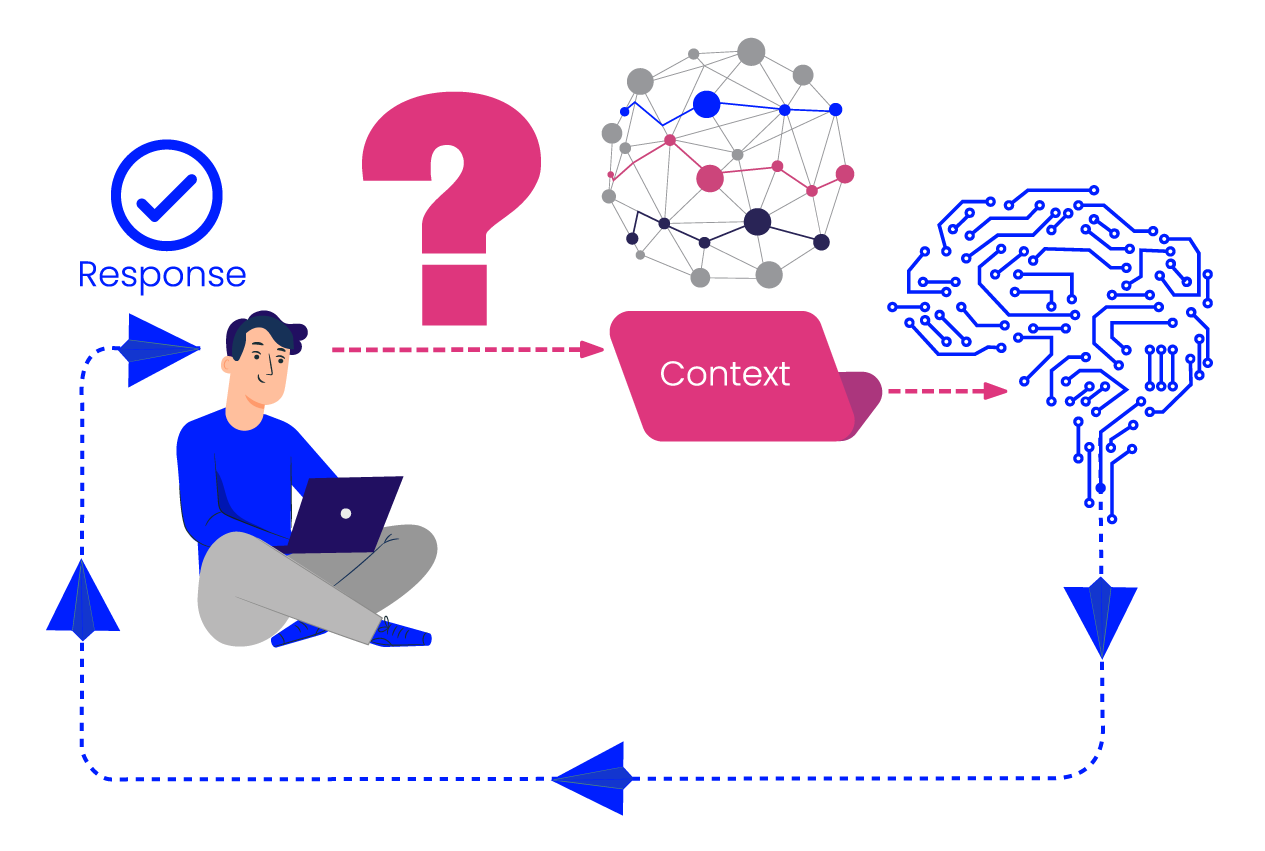
What Is GraphRAG?
Retrieval Augmented Generation enhances LLMs with external knowledge for more accurate, contextual question answering.
Read more
GraphRAG & Semantic Search
Demonstrates how a connected, semantically powered system helps employees find precise answers in seconds instead of digging through documents – while ensuring teams reuse approved knowledge instead of recreating it.
Read more
The Semantic Advantage: Scaling Enterprise-Ready GraphRAG and Trustworthy AI with Graphwise
Discover how Graphwise platform offers an enterprise-ready, low-code engine to operationalize explainable, governed and context-aware AI for the modern enterprise.
Read moreTransforming AI Reliability by Building Knowledge Graph-Powered Customer Support
Avalara used GraphRAG to establish a foundation for reliable, mission-critical AI applications in tax and financial services.
Read more
From Silos to Smarter Search and Self-service Tools
Using Graphwise offerings, Healthdirect Australia transformed its fragmented digital health infrastructure into a unified semantic knowledge graph.
Read moreGet more insights in the white paper
Download this white paper to discover how Graphwise platform offers an enterprise-ready, low-code engine to operationalize explainable, governed and context-aware AI for the modern enterprise.