Knowledge Graphs: Breaking the Ice
This post talks about the nature and key characteristics of knowledge graphs. It also outlines the benefits of formal semantics and how modeling graphs in RDF can help us easily identify, disambiguate and interconnect information
A graph is like a map that represents real-life objects and the relationships between them. While many of us use Google, Twitter, Alexa and Siri, likely most don’t know (or think about) that they are powered by knowledge graph technology. In these social network graphs, the objects are people and organizations, and the relationships are ‘follows’ or ‘friends’.
The objects in knowledge graphs are called “entities” and can represent real things in the world, events, situations or even ideas. The descriptions of these entities have a specific structure and meaning (semantics). This allows both humans and machines to process them efficiently and unambiguously. These descriptions also reference other entities and their descriptions and in this way create a vast network of knowledge.
The three roles of a knowledge graph
A knowledge graph is a versatile way of organizing and using data. It can act as a database, a network and a knowledge base depending on how it’s designed and used.
Like a database, knowledge graphs have schemas and users can apply complex structured queries to extract specific data needed. However, unlike relational databases, schema in a graph is flexible and it doesn’t need to be pre-defined.
The data in a knowledge graph can be represented as a collection of nodes and edges and can be analyzed like a network structure. This enables users to perform different graph algorithms, optimizations and traversal operations and transformations.
Because of the formal semantics attached to the data, knowledge graphs can act as a knowledge base. This enables humans and machines to easily interpret this data and derive new information.
Formal semantics
Formal semantics (usually defined by an ontology) establishes an agreement between the developers of a knowledge graph and its users with the context of the domain and the meaning of the data. Semantics utilizes a number of representation and modeling instruments to express and interpret the data of a knowledge graph.
A description of an entity usually includes its classification with respect to a class hierarchy. The idea is that each entity belongs to exactly one class (but can also be a superclass representing a higher-level concept or a subclass with a granular concept). For example, in domains like general news the most common classes are Person, Organization and Location. To continue along the hierarchy, both Person and Organization can have a superclass Agent, whereas Location usually has sub-classes like Country, City, etc.
The relationship between entities, on the other hand, are usually expressed by relation types. These indicate the nature of the relationship such as friend, relative, competitor, etc. Relation types can also have formal definitions. For instance, parent-of can be defined as the inverse relation of child-of and both can be considered specific cases of the symmetric relation relative-of.
Entities can also be associated with categories that describe specific aspects of their semantics. For example, a book can simultaneously belong to “Books about Africa”, “Bestseller”, “Books by Italian authors”, “Books for kids”, etc.
It’s also possible to include “human-friendly” free text descriptions in a knowledge graph. This helps further clarify the design intentions for an entity and offers additional context and details for enhanced search capabilities.
Knowledge graphs in RDF
One of the common graph data models is the Resource Description Framework (RDF). Developed and standardized by the World Wide Web Consortium (W3C), it provides a powerful and expressive framework for representing data and metadata.
RDF Basics
RDF is made of three-part structures called triples. An RDF triple consists of Subject, Predicate and Object. Each triple has a unique identifier known as the Uniform Resource Identifier (URI), which looks like a web page address.

Let’s consider the following example triples:
| subject | predicate | object |
|---|---|---|
| :Wilma | :hasSpouse | :Fred |
| :Wilma | :hasAge | 24 |
In the first triple, “Wilma hasSpouse Fred”, Wilma is the subject, hasSpouse is the predicate and Fred is the object. In the second triple, “Wilma hasAge 24”, Wilma is the subject, hasAge is the predicate and 24 is the object.
By connecting multiple triples together, we create an RDF graph. The following diagram illustrates the characters and relationships found in the Flintstones TV cartoon series. We see triples such as “PebbleFlintstone livesIn Bedrock” or “BamBamRubble livesIn Bedrock”. This tells us that the Flintstones and the Rubbles live in Bedrock and that Bedrock is part of Cobblestone County in Prehistoric America.
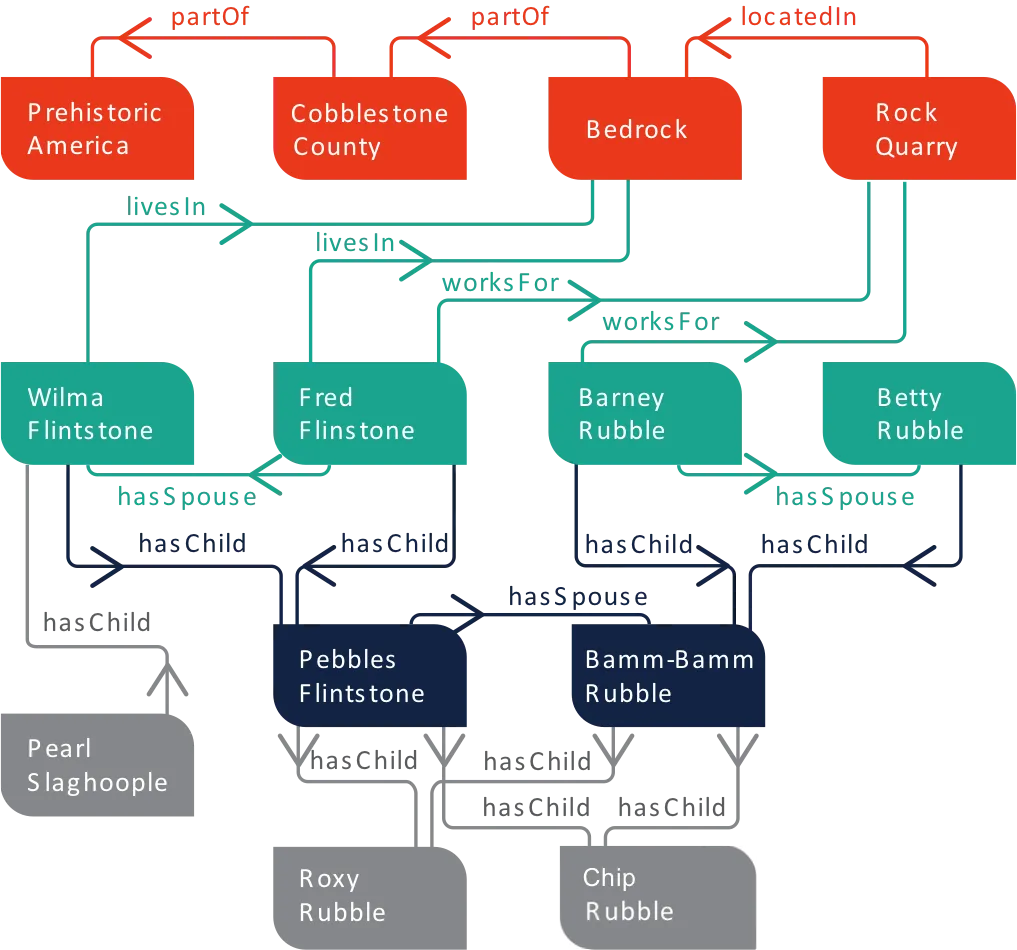
The other triples in the graph describe the relationships between the different characters (hasSpouse or hasChild) as well as their work association (worksFor). For example, we can see that Fred and Wilma are married, that they have a child Pebbles and that Fred works for the Rock Quarry company.
Labeled Property Graphs
Labeled Property Graphs (LPGs) are another graph data model that offers light-weight management of graph data. Its primary motivation is not centered around semantics, data exchange or publication, but is focused on efficient storage that enables quick querying and traversal of interconnected data.
LPG technology doesn’t have standardized schema or modeling languages and query languages, nor does it provide formal semantics and interoperability specifications. This means that there are no established serialization formats for representing LPGs. Because of this, there are no federation protocols for integrating data from multiple sources or other mechanisms to ensure seamless interaction and compatibility between different LPG implementations.
So this model is most useful when data needs to be collected on-the-fly and analytics is done within the scope of a single project.
The role of RDF-star
While RDF allows statements to be made only about nodes in the graph, LPGs can attach descriptions or properties to both nodes and edges. This is a major difference between the two models.
The introduction of the RDF-star extension resolves this gap, which now allows RDF to make statements about other statements. Now it’s possible to attach metadata to describe graph edges such as scores, weights, temporal aspects and provenance.

Break the ice and get to know your first knowledge graph!
Want to learn more about how to power your business with knowledge graphs?
