Efficient Discovery of Identifiers with the Autocomplete Tool in Graphwise GraphDB
Why the new autocomplete-based tool for Internationalized Resource Identifiers discovery matters, when to use it, and how it works
Finding the right Internationalized Resource Identifiers (IRIs) in large knowledge graphs can be challenging, especially with ambiguous or incomplete names. To address this, Graphwise GraphDB 11.1 introduces a powerful autocomplete tool designed for efficient IRI discovery. This tool is built for agentic chatbots navigating complex knowledge graphs and has already demonstrated its value across multiple domains.
Here’s why it matters, when to use it, and how it works.
Why use the autocomplete tool
This tool is designed to simultaneously tackle three key challenges in IRI discovery:
- Resolving ambiguity – identifies objects with non-unique or ambiguous names.
- Flexible searching – supports partial name searches and alternative labels.
- Optimized responses – reduces response size while preserving essential information.
It’s particularly useful for searching large knowledge graphs where entities (such as people, organizations, or places) may have similar names. By leveraging GraphDB’s autocomplete index and RDF Rank, the tool prioritizes the most relevant nodes, ensuring efficient and meaningful results.
When to use the autocomplete tool
With the introduction of autocomplete, Talk To Your Graph (TTYG) now includes four tools for IRI discovery, each serving a distinct purpose:
- Full-Text Search (FTS) – performs fast searches across literals and IRIs, making it the broadest and least specialized tool.
- Similarity Search – finds IRIs based on semantically similar associated texts, helping to connect key terms in longer documents.
- IRI Discovery – extends FTS but focuses specifically on retrieving IRIs.
- Autocomplete IRI Discovery – addresses two key challenges:
- Handles questions that reference entities without exact name match.
- Navigates knowledge graphs with many entities that share similar names.
Tool comparison
While FTS provides broad access to data, and similarity search connects relevant text fragments, IRI discovery and autocomplete are tailored specifically for handling names.
To illustrate their differences, let’s compare these four tools using a large dataset of company, investment, and funding data — spanning 200M triples and over 5M persons and organizations.
| Exact Name | Colloquial Name | |||
|---|---|---|---|---|
| Accuracy | Avg Tokens | Accuracy | Avg Tokens | |
| FTS | 0.98 | 24844 | 0.85 | 23997 |
| Similarity | 0.98 | 24850 | 0.93 | 24381 |
| IRI discovery | 0.98 | 23435 | 0.97 | 23703 |
| Autocomplete | 1 | 4161 | 0.98 | 4059 |
The data in the table shows the performance of each tool on a dataset of 100 top investors. In each case, a large language model (LLM) was asked to identify the correct IRI for a given investor.
Exact Name Matching: When provided with the full, exact name, all tools successfully retrieved nearly all investors. However, the autocomplete was the only tool to achieve a perfect success rate while using just one-sixth of the tokens required by the alternatives — making it significantly more efficient.
Colloquial Name Matching: When given only a colloquial or abbreviated name (such as “UC Berkeley” instead of “University of California, Berkeley”), FTS and Similarity Search began making more errors, whereas the specialized IRI discovery tools still retrieved nearly all results correctly.
Insights from experience
But why did the autocomplete miss two IRIs? The issue wasn’t with the tool — it was a limitation of the database itself. For example, when the query contained “MIT”, the correct IRI existed, but only under the full name “Massachusetts Institute of Technology”.
If the existing IRI discovery tools perform nearly as well, why use autocomplete? The key advantage lies in token efficiency. The first three tools consume a similar number of tokens because they hit a response size limit. While increasing this limit might improve their performance, it’s constrained by the LLM’s context window — and in large knowledge graphs, the full dataset simply won’t fit.
By comparison, autocomplete has the following advantages:
IRI identification is often just an intermediate step in complex query building. This process may need to be repeated multiple times before the final query can be prepared.
Using fewer tokens reduces cost and improves speed, while also ensuring enough context remains for a large prompt and carrying out the final task.
Context window efficiency: For example, GPT-4o has a 128,000-token context window, yet a single response from the first three tools can take up nearly 20% of it. Autocomplete, in contrast, can be run multiple times while still using fewer tokens overall.
By optimizing token usage, the autocomplete ensures that real-world queries remain feasible within an LLM’s constraints — making it the superior choice for IRI discovery at scale.
How to use the autocomplete tool
Now, let’s set up a chatbot that fully leverages the autocomplete tool for IRI discovery.
To begin, we’ve loaded a fresh instance of GraphDB 11.1 and uploaded the dataset. Before creating the chatbot, we need to build the necessary indexes that the autocomplete tool relies on.
First, we create an autocomplete index and add our dataset’s custom name predicates to it to ensure everything gets indexed.
Next, we compute RDF Rank over the repository. This step is essential for ranking results by importance, ensuring that the most relevant IRIs appear among the top results. By doing this, we maximize the chances that the correct IRI is identified quickly and efficiently.
Now, we are ready to create our agent using the autocomplete tool. To ensure optimal performance, we:
Enable both the autocomplete and the SPARQL query tools
Provide the ontology for better understanding of the dataset
Include instructions on the dataset’s structure and how to handle user queries effectively
With these configurations in place, the chatbot is ready to answer our questions.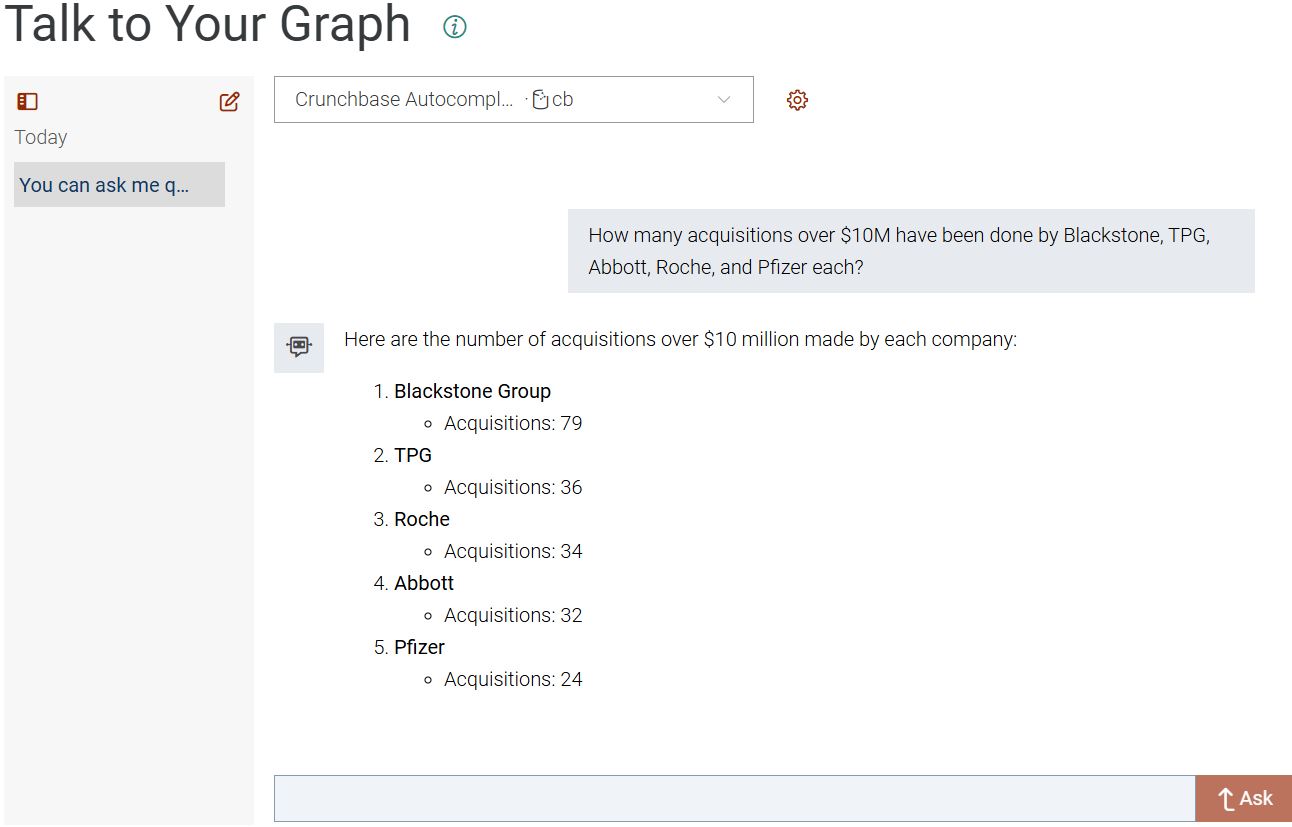
And in just a few minutes, we have a brand new assistant ready to answer questions. The question above asks the chatbot to find the IRIs for five companies using shortened names, then write a complex aggregation query with a filter on acquisitions performed by the companies. In seconds, we get our counts and can continue the conversation, have it refine the query, or show us how the data was collected.
Main takeaways
The autocomplete tool in GraphDB 11.1 revolutionizes IRI discovery by optimizing for both speed and efficiency. It stands out for its ability to resolve ambiguous names, handle partial or colloquial names, and deliver highly relevant results with minimal token usage.
By integrating this tool into a chatbot, you can quickly retrieve IRIs, construct complex queries, and streamline data exploration — all within seconds. This not only saves time and resources but also ensures that complex tasks can be tackled seamlessly, even with large knowledge graphs.
Want to check it out?
