Advancing Research Activities for Identifying Novel Therapies
NuMedii used GraphDB to build a knowledge graph that enabled efficient identification of new therapies by unifying fragmented public and proprietary biomedical data
The Client
Biotech company focused on AI-driven drug discovery for new therapies for complex diseases
The Challenge
NuMedii needed to efficiently identify novel treatments by integrating and extracting meaning from a vast, fragmented, and redundant array of structured and unstructured biomedical research data
The Solution
NuMedii leveraged Graphwise’s GraphDB to build a knowledge graph, integrating 20+ biomedical databases & scientific literature, dynamically enriched by extracted and normalized data
Technical capabilities
- Built a 7.98 B-triple Knowledge Graph integrating 20+ databases
- Implemented semantic data modeling & text analysis pipelines to annotate literature & enrich the KG
Business outcomes
- Increased efficiency and cut time/resources on research activities
- Enabled hidden knowledge discovery, pattern identification & hypothesis testing
The Challenge
NuMedii was looking for a smart solution for analyzing research literature that would facilitate the identification of new therapies for treating idiopathic pulmonary fibrosis (IPF). The required solution had to be able to leverage both structured (from public and proprietary datasets) and unstructured data (from scientific journals).
There were various challenges in achieving this goal:
- Providing provenance for each underlying fact supporting the scientific conclusions
- Rapidly growing number of data and sources with genomic, molecular, and other biomedical data describing diseases and medicinal drugs
- Highly fragmented nature of the data coming from multiple sources
- Frequent occurrences of semantic redundancy (ambiguity)
- Time- and effort-consuming aspects of data integration processes as well as maintaining such knowledge on a large scale
- Efficiently extracting relevant meaning from the acquired knowledge
The Solution
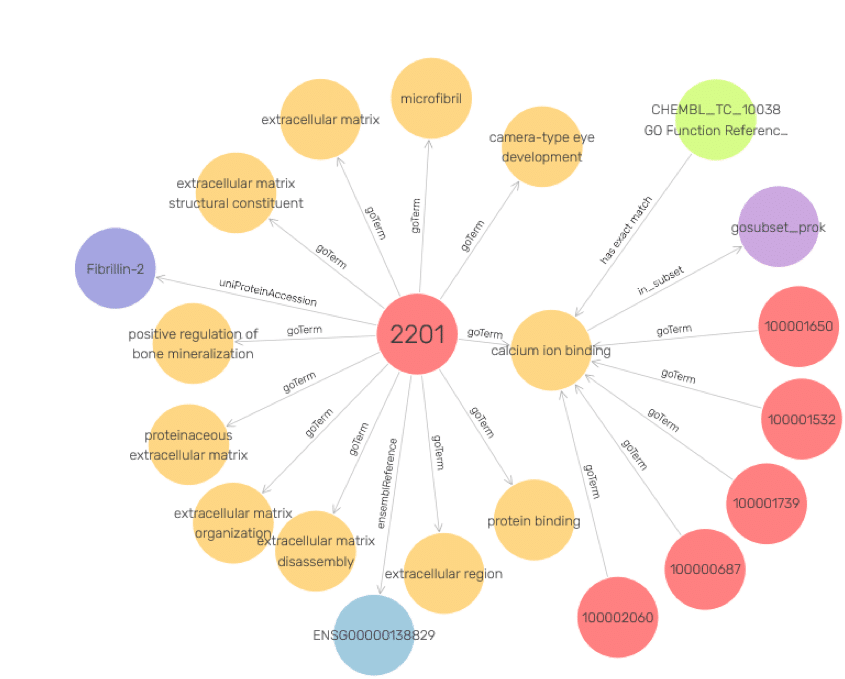
In 2017, as part of the project, NuMedii used Graphwise’s GraphDB to build a knowledge graph integrating over 20 open and commercial public databases, as well as proprietary datasets, covering genomics, proteomics, metabolomics, diseases, and drugs.
This involved semantic data modeling to normalize diverse data schemas and instances to major biomedical ontologies.
Graphwise’s GraphDB also created extensive semantically annotated scientific literature corpora, which, combined with the knowledge graph, enabled advanced text analysis pipelines to identify and infer new biomedical concepts and relationships.
The Impact
NuMedii significantly increased its efficiency in identifying novel therapies and cut time and resources on research activities.
The solution improved user experience by providing access to highly normalized and semantically interlinked data, facilitating the discovery of knowledge locked in disparate documents, enabling pattern identification, and supporting hypothesis testing for IPF treatment.
Details
Facing Similar Challenges?
Struggling to unify vast, complex, and fragmented biomedical data from diverse sources? Whether you're a biotech company, pharmaceutical research organization, AI-driven drug discovery firm, or life sciences company, Graphwise can help you:
- Unify all your R&D data into a comprehensive, industry-specific knowledge graph
- Automate the extraction of insights from unstructured scientific literature
- Discover new patterns and infer novel facts to accelerate drug discovery
- Feed AI and analytical tools with high-quality, traceable data for confident decision-making