Check the Fakes or How AI and Knowledge Graphs Bring Information Integrity
Learn about Graphwise’s contributions to EC-funded projects on combatting disinformation
Main Takeaways
- Disinformation actors reuse the same narrative across languages — the same misleading message gets adapted to local contexts, so fighting it requires connecting concepts across languages, not just flagging individual posts.
- A knowledge graph turns scattered claims into a navigable map — by linking concepts, events, and similar stories, analysts can see how narratives spread, cluster, and evolve over time in ways keyword search cannot reveal.
- Event extraction goes beyond who said what — detecting structured events (attack, injury, regulatory change) embedded in claims reveals the underlying narrative logic that makes disinformation persuasive.
- Grounding the AI agent in the knowledge graph ensures trustworthy answers — the chatbot can only reason over what's in the verified database, making its outputs factual and explainable rather than probabilistic.
The World Economic Forum Global Risks Report ranks misinformation and disinformation among the five most impactful technological risks for the next 10 years. While the rise of GenAI technologies has made the work of malicious actors more convincing and prolific, the “good guys” have also harnessed their AI faculties to fight back.
Graphwise has had its share in addressing this growing societal challenge through leveraging its semantic technology and AI research expertise in EC-funded initiatives. In the last three years, our Innovation team has led the development of AI-based tooling to empower:
- Fact-checkers and disinformation researchers (in vera.ai, BROD, FactCRICIS)
- Police authorities (in VIGILANT)
Thanks to identifying concepts, events, and similar narratives and interlinking them in a knowledge graph, this tooling helps unlock new analytical capabilities across multiple languages. We have integrated all these capabilities in the Database of Known Fakes (DBKF) and have made them accessible through a user-friendly interface. It makes it easy to double-check whether a claim has already been debunked by trusted fact-checkers.
Now, let’s put ourselves in the shoes of the user and take a closer look at our tooling. We’ll follow the investigative journey of an analyst interested in some misleading stories around renewable energy.
Linking and discovering concepts across languages
Our analyst conducts his study in a multilingual setting and on a large dataset. So, he needs to be sure that the results he gets from this database will contain the same concept, “renewable energy”, across all languages of the dataset. To address such a need, we have designed a multilingual entity linking model. It detects, disambiguates, and links named entities and other general concepts mentioned in text to a common knowledge base (Wikidata) across different languages. The connections between the instances of concepts in the different languages are stored in the knowledge graph so our DBKF can respond to the “renewable energy” query in the blink of an eye.
This interlinking of the information in the knowledge graph allows for deriving additional insights. For example, which concepts are mentioned together with the queried one. Or in what context the queried concept occurs or how its mentions are distributed over time.
DBKF provides a visual way of exploring all these aspects, including concept “quotes” (excerpts from the text with the immediate context) as shown in the screenshots below.


Based on the currently available data in the DBKF repository, our analyst can unravel some interesting and very different stories. For example, in the German context, the misleading statements revolve around how renewable energy installations are not capable of a black start after a blackout. It also talks about the allegedly non-recyclable rotor blades of wind turbines or speculates about carbon tax. The Polish context, on the other hand, offers misinformation about the Polish government’s achievements in increasing the share of renewable energy in the country’s energy mix.
This brings us to the next useful enrichment of the data: detecting not only objects or subjects, but related actions.
Spotlighting real-life events
For the needs of our target end users in the VIGILANT project (police authorities analyzing disinformation that has the potential to instigate criminal activity), we developed a state-of-the-art event extraction algorithm. It helps them uncover who did what, when, where, and why.
We built upon the Text2Event transformer model, which is pre-trained to detect 33 event types. In order to address some of the most common narratives found in disinformation content, we fine-tuned the model to extract 3 additional event types. These included pinpointing claims of miracle cures, severe weather phenomena, and regulatory or legislative changes that affect a broader subset of society, such as the Paris accords or the introduction of vaccine passports.
So now our fictional analyst may want to find out if events such as “attack”, “die”, and “injure” get frequently associated with his research. Claims like “falling blades from failing wind farms could be launched your way at any moment” could mislead people into believing that if they live near wind turbines, they are at risk of injury or death. Similarly, information that solar panels cause fire outbreaks raises questions about their safety.
In DBKF, we provide excerpts with event “quotes”, highlighting the word that denotes the event trigger. You can see some examples in the following screenshots.


Although they are not highlighted, we also store the event arguments (actors, targets, places and so on), which can be used to further filter the identified events. This information is interlinked with the raw text in the claims (the short misleading statements), the claim reviews (the whole debunking articles), and the extracted concepts in the knowledge graph. This is illustrated in the following diagram.
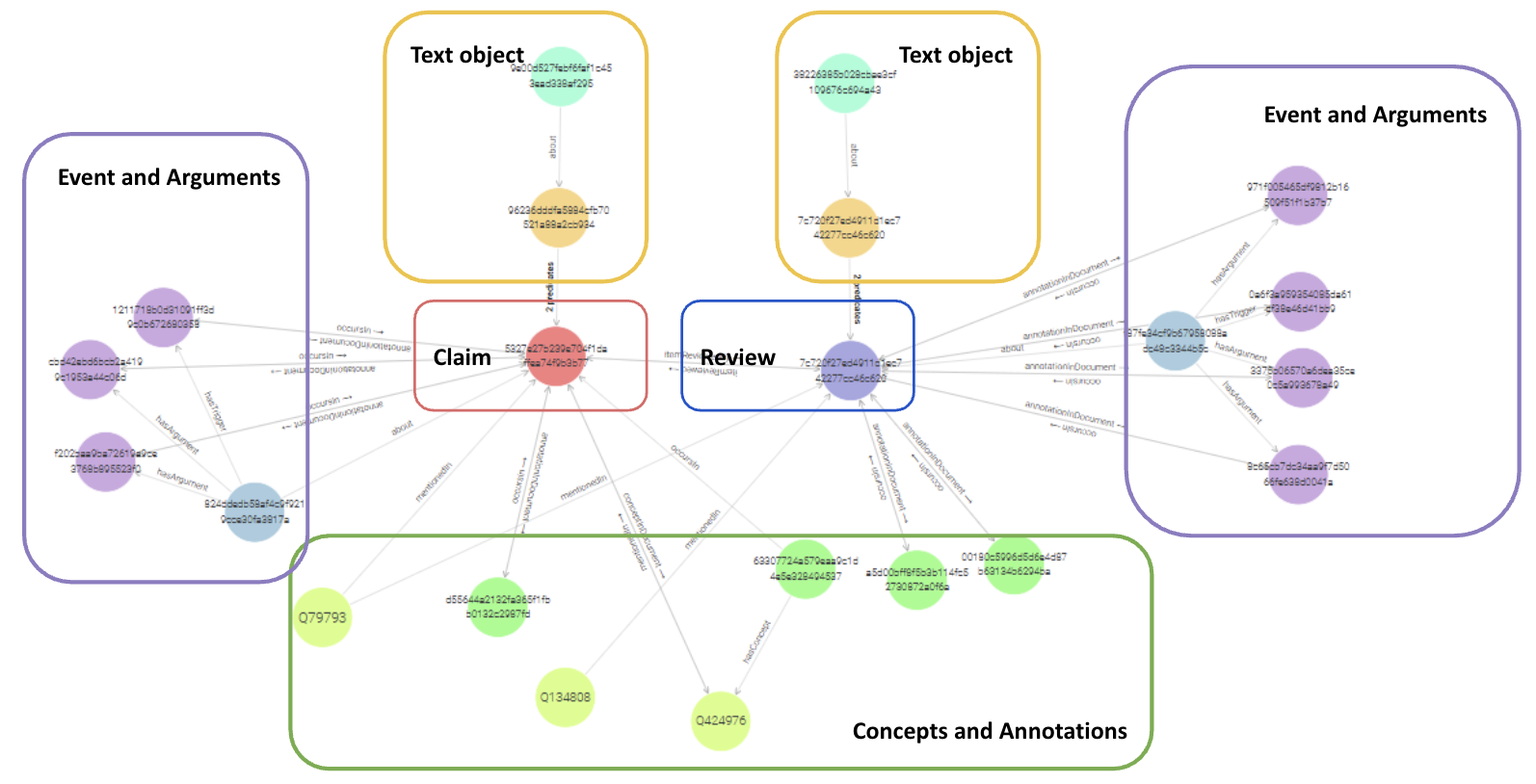
This offers great flexibility in terms of designing complex faceted searches. Analysis of results from such searches can offer additional insights about narratives within and across documents that were previously hidden. This opens up a new level of content analysis, in which we can group similar stories.
Identifying clusters of similar content
While the disinformation covered by debunks globally varies greatly, there is also a significant overlap in the key concepts addressed by debunks. This is because disinformation actors tend to reuse content and adapt it to specific contexts but leave the underlying message the same. These patterns are very useful to detect when tracing the spatio-temporal dynamics of disinformation campaigns and narratives. Such an analysis can be relevant in other domains, which require identifying and grouping similar pieces of textual content across different languages, geographical regions, and time periods.
Our Innovation team has devised a sophisticated clustering algorithm, intended to produce clusters of closely tied claims. It was specifically chosen for its ability to handle large datasets and multilingual data.
The cluster building process follows four main steps:
- Document chunking and embedding calculation to capture the semantic information of the text
- Cluster creation with a GPU-enabled version of the HDBSCAN algorithm
- Cluster naming using a local Small Language Model
- Cluster metadata calculation based on the knowledge graph. This metadata includes key concepts, authors, languages, and the start and end dates of cluster activity. Such information enriches the clusters, providing valuable context and insights for further analysis.
The DBKF user interface enables our analyst to explore the relevant clusters and the associated metadata. It also helps track the evolution of the narrative through an intuitive timeline visualization like the one shown in the screenshot below.
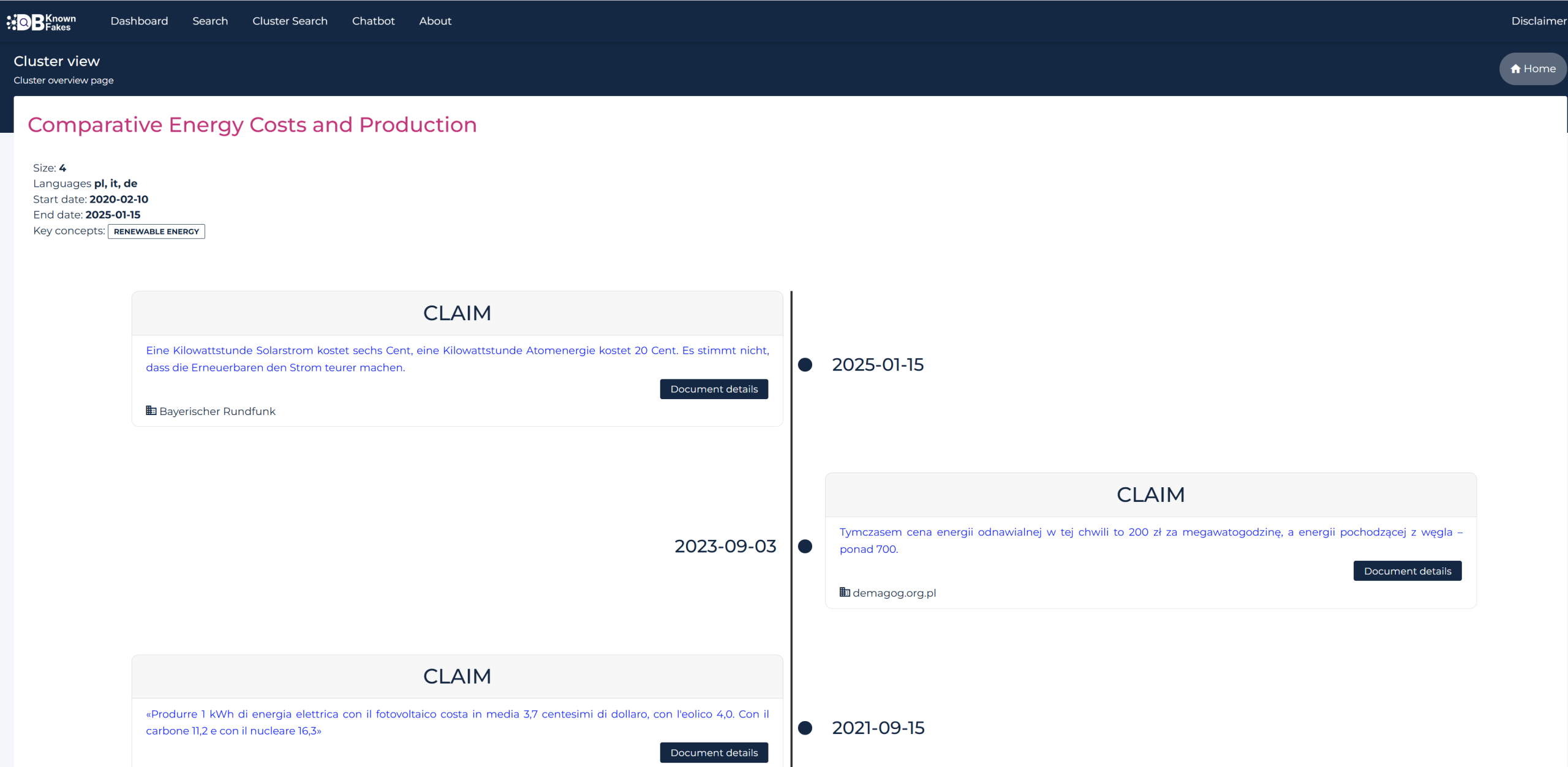
Going one level up (before this cluster view deep-dive) the user can see listed all the recurring narratives. They revolve around misconceptions about renewable energy sustainability, common causes of blackouts in renewable energy systems, inconsistencies in renewable energy targets and achievements.
At this point of his investigative journey, our analyst may want to explore this tooling in other ways such as aggregations or breakdowns by language. Or he may be interested in other metadata and enrichments. This is where our trusted AI assistant: the DBKF chatbot comes in.
Querying data with the help of an AI assistant
We have built a customized AI agent based on GraphDB’s Talk to Your Graph functionality. This agentic chatbot has access to all the search functionalities available through the DBKF user interface, as well as direct database access. It is designed to help users perform complex, multi-tool interrogations of the data, providing a more interactive and guided experience.
The DBKF chatbot is prompted to answer requests only related to the contents of the database and to base its reasoning on the information available in the underlying knowledge graph. Grounding the AI agent through the knowledge graph ensures factuality and explainability of answers.
Our analyst can feel at ease talking to the AI assistant in whatever natural language he prefers. In this way, he will gain deeper insights on the topic of his research.
The conversation with the chatbot can serve as his entry point into the rich capabilities of DBKF as well as an incremental introduction to its advanced features. Retrieving the ten biggest claim clusters discussing renewable energy can be the start of a more in-depth exchange, spanning all the possible connections in the database (see the screenshot below).
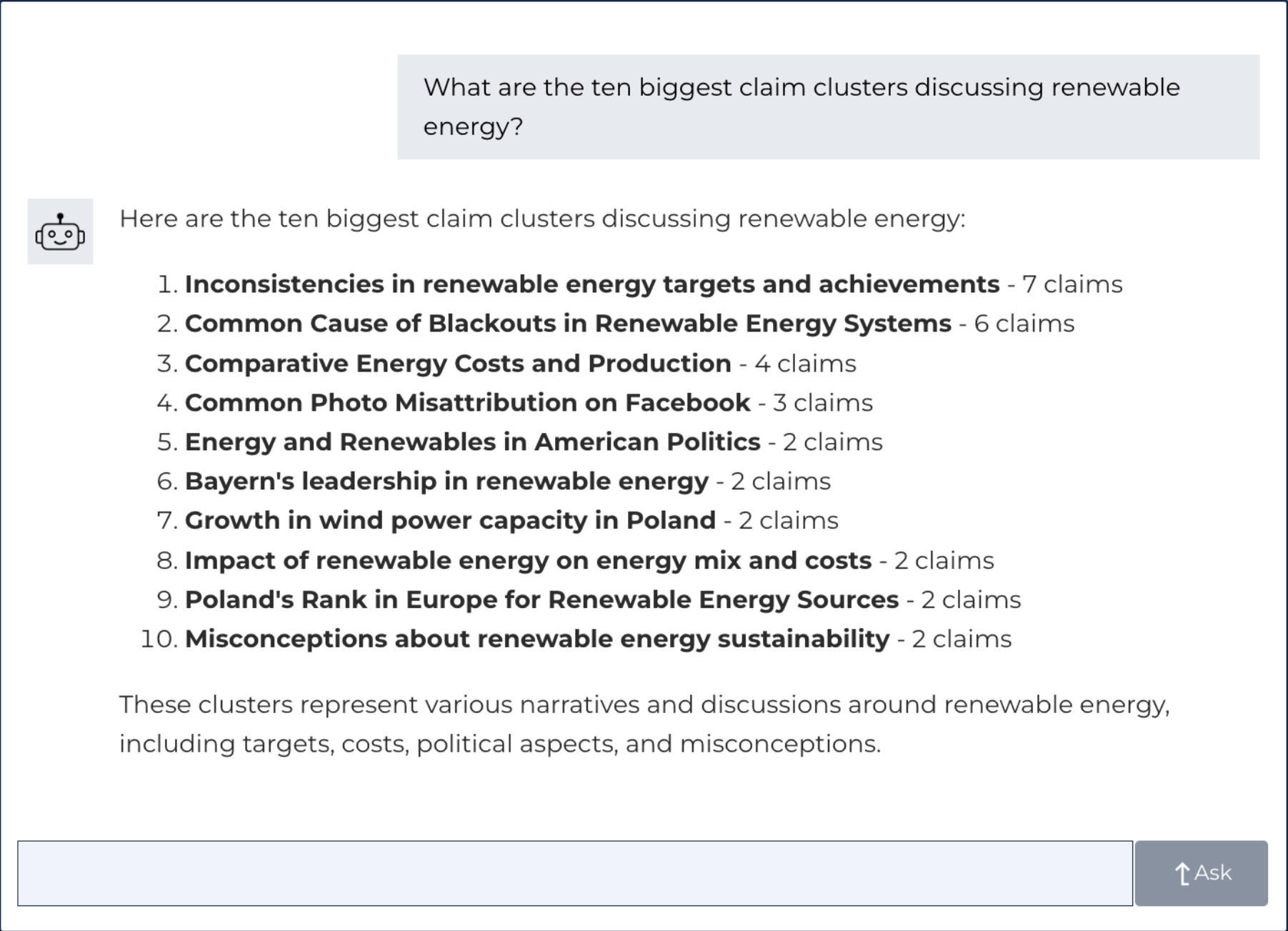
Conclusion
Through our work in the counter-disinformation projects, we have developed practical solutions for users, who need to perform analysis on a huge amount of data in multilingual settings.
By identifying and using the connections between concepts, events, and similar stories, we can facilitate the exploration of data in other domains in addition to media content. Providing structure and grounding for the AI agent through the knowledge graph, we ensure accurate and trustworthy answers.
Curious to see how this tooling works in action?

Details
What is a Knowledge Graph
Knowledge graphs are a collection of interlinked descriptions of entities that put data into context and enable data analytics & sharing.
Learn moreRecommended Content

My Dear Watson, it is Great to Have Someone to Talk to
Learn how we empower users to sift through a large pool of data with the help of our Talk To Your Graph agent.
Read more
AI-ready Graph Environments: The Key to Scaling AI with Graphwise’s Knowledge Graphs
Read about why most enterprise AI fails and how Graphwise creates graph environments using knowledge graphs and semantics.
Read more
Beyond the Chatbot: Why Marta is the Smarter Way to Navigate Graphwise
Read about our AI assistant designed to give instant, contextually accurate answers about our products, use cases & business value.
Read moreFAQ
Any Questions? Look Here
AI is used to detect disinformation and fake news by combining Natural Language Processing (NLP) with semantic technologies like knowledge graphs to extract and interlink claims, events, and narratives across multiple languages. Advanced systems, such as those developed in projects like vera.ai and VIGILANT, utilize multilingual entity linking and clustering algorithms to track the spread of manipulative stories and identify coordinated sharing behaviors. These tools often feed into centralized repositories like the Database of Known Fakes (DBKF), which allows fact-checkers to verify claims against previously debunked content and detect synthetic media (deepfakes) using multimodal analysis. By providing a structured, explainable context for information, AI helps automate the identification of information integrity risks and streamlines the verification process for journalists and authorities.
Fact-checkers leverage knowledge graph technology to verify claims at scale by transforming unstructured information into a structured, interlinked network of entities, events, and relationships. By using automated event extraction and natural language processing (NLP), claims are mapped onto a referential baseline of verified facts and domain-rich ontologies, such as the Database of Known Fakes (DBKF), which aggregates tens of thousands of debunks across multiple languages. Advanced frameworks like FROCKG (Fact Checking for Large Enterprise Knowledge Graphs) combine machine learning with large-scale incremental indexing and consistency checks to quantify the veracity of new information, surfacing hidden patterns and narratives within vast datasets. This approach enables fact-checkers to move beyond manual verification, providing explainable and traceable evidence by grounding claims in a unified semantic layer that connects disparate data sources and reliable evidence.
Knowledge graphs significantly enhance misinformation research by providing a structured semantic framework that interlinks diverse data sources—including claims, debunks, news articles, and social media posts—to surface hidden relationships and provide critical context. By leveraging technologies such as multilingual entity linking and event extraction, researchers can track the evolution and spread of disinformation narratives across different languages and cultural regions, facilitating more robust and accurate fact-checking. Furthermore, Knowledge graphs serve as a transparent "context engine" that grounds AI models and analytical tools in a verifiable web of interconnected facts, enabling the detection of complex patterns of manipulation while ensuring that findings are explainable and evidence-based.
Generative AI significantly amplifies the dangers of disinformation by drastically lowering the barriers to creating highly realistic, prolific, and persuasive deceptive content at scale. By leveraging technologies like deepfakes and advanced large language models, malicious actors can produce synthetic audio, video, and text that are increasingly difficult to distinguish from authentic media, thereby making manipulative narratives far more convincing to the public. This "hyper-realism," combined with the ability to rapidly adapt and automate the spread of misinformation across languages and contexts, complicates the work of fact-checkers and undermines social trust, making it one of the most impactful technological risks to global stability and democratic processes.