


This article was originally published in TCWorld.
Large Language Models (LLMs) and Generative Artificial Intelligence (GenAI) are the major focus of today, not only in technical communication. They promise to solve everything and cost almost nothing compared to metadata or master data management projects.
But how accurate is the information produced by LLMs? Accuracy is crucial, particularly for safety-critical information in technical documentation. In this article, we will compare the accuracy of information produced with three different systems: a standard LLM; a standard GenAI retrieval mechanism using structured data with DITA; and a trusted knowledge base using structured data with DITA enriched by iiRDS to retrieve the right context for optimized GenAI output.
We will reveal how a knowledge-based approach to enriching DITA in combination with iiRDS produces far more accurate results, which is vital for safety-related information.
What is Intelligent Information and why do we need it?
Intelligent Information is information that is contextually retrievable, thus helping users to find the specific information they need to solve a problem.
Various developments have greatly increased the need for Intelligent Information: First of all, due to the heavy usage of digital devices, Generation Z has shorter attention spans than previous generations. Secondly, we are facing an upcoming skills shortage due to the retirement of the baby boomer generation, which will lead to a gap in practical knowledge. Moreover, current upskilling processes will no longer work.
Just consider the following case that is quite common in our industry: In former times, out of a service team of ten technicians, one retired per year and was replaced by a young one. The new member was trained for half a year, and the other nine technicians took over the additional work until the new recruit was fully trained. Nowadays, however, we are facing a scenario in which out of a team of ten service technicians, six to seven will retire over the next three to four years, causing drastic workforce shortages.
As the only solution to solving this brain drain, newcomers need the right information, in the right context, at the right moment, and in the right output format, to be productive right from the start. For that, a trusted retrieval and recommendation mechanism is essential.
Is AI a valid answer to everything?
In the hype of OpenAI’s ChatGPT, GenAI/LLMs are seen as a panacea for everything. However, LLMs are showing numerous drawbacks:
- They lack traceability and explainability of their results. Traceability is a legal requirement in heavily regulated sectors, such as medical technology.
- LLMs seem to struggle with sequences. Sequences are necessary to retrieve the right order for task instructions. If mixed up, this might compromise safety.
- LLMs have no sense of the varying magnitude of importance of different content. In machinery, for example, it is a legal requirement to have hazard statements in the right place.
Solving these issues requires a lot of money and resources for additional training as well as for the search of suitable prompt chains.
Introducing Trusted AI
So, how can we counter the flaws of standard LLMs?
In order to find the best solution, we have put several LLM scenarios to the test. For our studies, we used a SANDVIK bolter miner and its documentation. In this scenario, hydraulics work is dangerous due to the high pressure of the hydraulics oil and the fact that you cannot see a pressurized oil stream coming through a pinched hose. Troubleshooting for such hydraulics systems is complex and a fault can have different causes. Also, it is highly important to retrieve the right warnings in hazardous situations.
For this study, we investigated the accuracy of the information produced by
- An LLM alone
- An LLM optimized with standard (vector-based) Retrieval-Augmented Generation (RAG)
- An LLM optimized with an iiRDS-based RAG, where we enriched DITA topics and maps with the corporate taxonomy, mining-specific domain taxonomy, and the iiRDS core and machinery ontology to establish a knowledge graph that optimizes the retrieval of context for the RAG system.
By referencing a corporate knowledge base, the iiRDS RAG selects the specific relevant iiRDS-tagged content. Thus, only trusted knowledge is fed into the LLM, resulting in what we call Trusted AI.
Bringing iiRDS and GenAI together
We created iiRDS entities and relations from the topics in our technical documentation as well as additional e-learning nuggets. These were stored as a knowledge graph in a graph database.
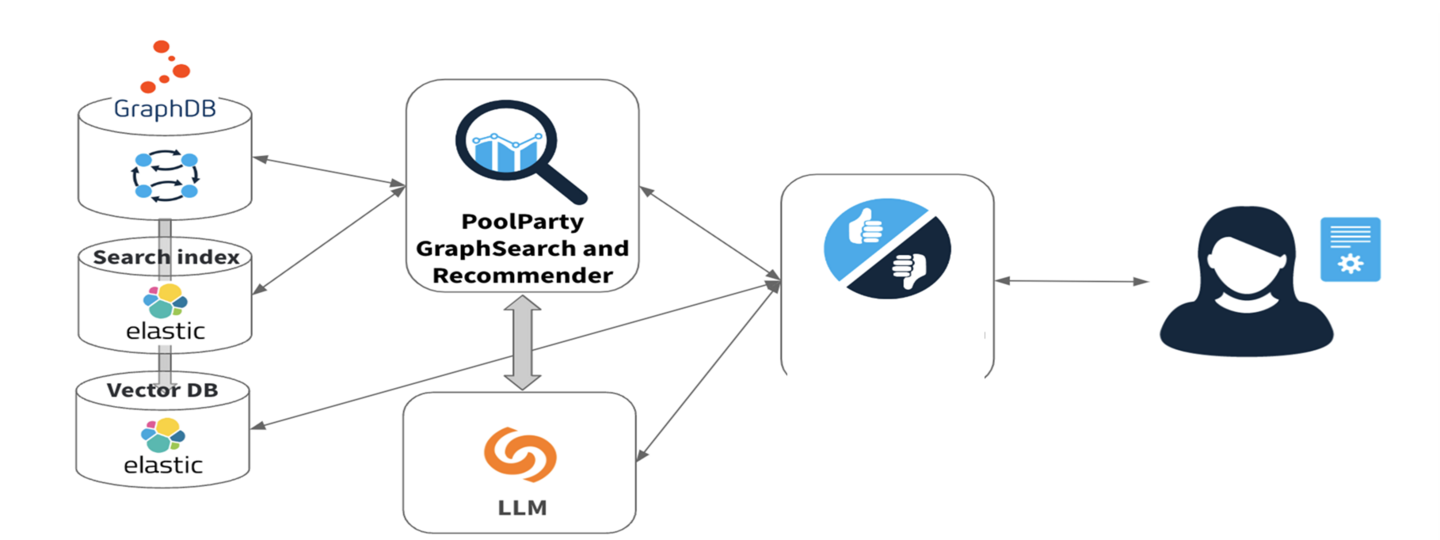
Figure 1: The iiRDS RAG pipeline
What are the results?
Using the content (DITA topics) of the operating manual of a bolter miner, we tested the three scenarios:
- LLM alone
- Vector-based RAG with an LLM
- iiRDS-based RAG with an LLM (i.e., a Graph RAG based on iiRDS).
As you can see in Figure 2, the results were overwhelming.

Figure 2: Performance comparison (LLM only vs. vector-based RAG vs. iiRDS-based RAG)
Due to its trusted basis of input, iiRDS-based RAG scored far better than all the others. Adding more granularity to the hazard statements can raise the percentage of awareness even further.
Conclusion
Our study shows that iiRDS as the only existing standard schema for the retrieval of technical information secures the best LLM output taken from the basis of technical documentation. [1] Interfacing iiRDS with the language capabilities of LLMs promises accurate results in the right context, at the right time – and future-proof solutions.
References
[1] IEC PAS 63485:2023 – Intelligent Information Request and Delivery – A process model for the exchange of information for use, 2023.
