Advancing Power System Analysis with AI and Semantic Data
How Talk2PowerSystem uses AI to simplify complex power system engineering
Main Takeaways
- Natural language replaces complex manual SPARQL queries
- Simplified ontologies make LLMs significantly more accurate
- Semantic shortcuts collapse deep data hierarchies reliably
- GeoSPARQL adds spatial context and map-based visualization
In the evolving landscape of the energy sector, the ability to efficiently interact with complex data models is becoming a necessity. This blog post explores the Talk2PowerSystem project, a collaboration between Statnett and Graphwise, that creates AI-based tools and methods to automate the analysis of complex power system models and deliver actionable insights for engineers.
Through the synergy of large language models (LLMs), Semantic Web technologies, and geospatial standards, Talk2PowerSystem aims to revolutionize the analysis of grid data. Today, power system engineers rely on the Common Information Model (CIM) — a robust but incredibly complex framework of standards (IEC 61970, 61968, 62325). While CIM is the gold standard for data, its sheer size makes crafting graph queries a daunting task for even the most seasoned engineers. Our vision is to let experts query these models using natural language instead.
Delivering on that vision of natural language querying is not straightforward: industry-standard ontologies are enormous, and while LLMs open up new ways to interact with knowledge graphs, their context windows are limited — feeding them verbose schemas can lead to confusion or lost instructions. In the rest of this post, we present three important aspects of our approach in Talk2PowerSystem:
- simplifying ontologies so LLMs can digest them efficiently,
- applying semantic reasoning to collapse deep CIM hierarchies into query-friendly shortcuts, and
- grounding the model in physical space with GeoSPARQL to unlock spatial querying and visualization.
Simplifying ontologies for LLMs: Lessons from the field
To enable a chatbot to reliably query complex ontologies, we needed to make them “LLM-friendly”. CIM for the electrical grid consists of over 20 parts (profiles) with a lot of duplication and complexity. Their union has over 900 classes and 5500 properties, but an actual grid data would use less than half of all ontology terms.
It is not only in CIM. Other standard ontologies, such as the ERA Vocabulary, are also designed for completeness. They often contain:
- Long descriptions of regulations
- Administrative metadata (creation dates, XML mappings)
- Translations in multiple languages
- Many unused classes and properties
When an LLM processes this raw data, it consumes many tokens and can lose focus on the relevant structure. We used a pipeline to clean and simplify the ontology before presenting it to the AI and employed the following key optimization strategies:
- Pruning textual descriptions: An effective way to save tokens is shortening
rdfs:commentfields by cutting descriptions at approximately 400 characters using SPARQL regex updates. This removes excessive legal citations or historical notes that do not help the LLM understand the current data structure, ensuring that the model focuses on the core definitions of entities. - Removing “bookkeeping” metadata: Ontologies are often cluttered with administrative data such as
dct:modifieddates, creator names, and contributor lists. While vital for governance, this information is “noise” for an LLM trying to generate a query. Deleting these properties significantly compacts the schema. - Enhancing presentation and formatting: The way Turtle (RDF) is serialized matters. Standard serializations often produce “ugly” output — scattered definitions, unordered terms, and confusing blank nodes for OWL restrictions. We recommend using tools like
turtle-formatterto group classes, properties, and individuals logically and alphabetically. “Prettier” schemas lead to higher accuracy in query generation. - Ontology subsetting: Large-scale ontologies like CIM contain thousands of classes. However, specific datasets often use only a fraction of them. By subsetting the ontology – including only the classes and properties which are actually instantiated in the knowledge graph- developers can drastically reduce the token load.
By removing noise and reducing the size of the schema to 285 classes and 445 properties, we improved the LLM’s ability to generate correct SPARQL queries. A cleaner schema also saves tokens and helps the model focus on the relevant data structure. Further details of our approach can be found in this detailed technical blog: Simplifying Ontologies for LLMs: Lessons from the Field.
Beyond simplifying the schema, the project also had to address the logical complexity of how data is interconnected.
Using semantic reasoning to simplify LLM SPARQL generation for electrical CIM
We apply custom semantic reasoning to CIM in order to simplify deep graph hierarchies into manageable “shortcut” relations, making the data model more manageable for querying by LLMs.
The challenge: Deep nesting and long traversals
As already discussed, CIM is a robust standard for representing the entire electrical enterprise. However, its granularity makes querying difficult. A simple request like “List all substations connected via an AC-line to substation X” requires navigating a deep hierarchy of objects:
- Substations contain VoltageLevels, which contain Bays, which contain Equipments
- Equipments connect via Terminals to ConnectivityNodes, which connect to other Terminals of other Equipments
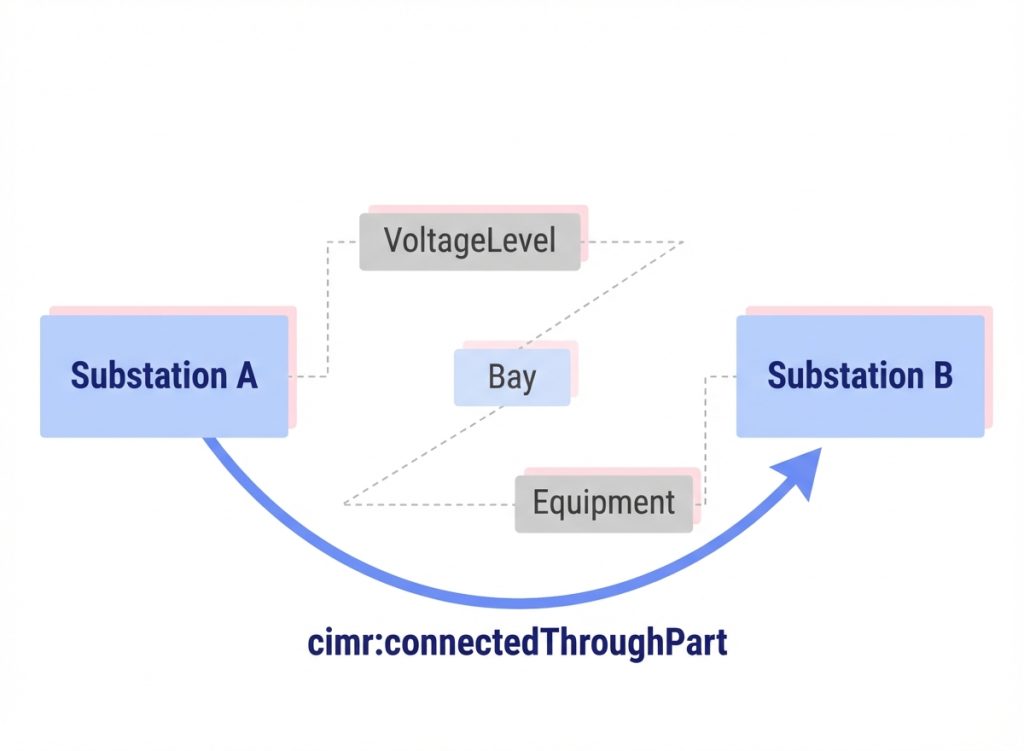
In order to answer the request, a raw SPARQL query needs to traverse from a Substation “down” to its parts, to Terminals and ConnectivityNodes, then “up” to parts of Lines (called ACLineSegment), “down” the other side of the Line, and “up” to the other Substation. This involves multiple unions, transitive closures, and property paths.
While execution is fast (approximately 0.1s), the query structure is too complex for LLMs to generate reliably. LLMs often produce syntactically correct but inefficient or semantically incorrect queries when faced with such deep nesting.
The solution: Semantic reasoning and inference
To address this, we implemented standard OWL2 RL rules to introduce “shortcut” relations that simplify the graph structure for the LLM without altering the underlying data model.
We defined a new namespace cimr: (CIM Rules) and added the following inferred relations:
- Super-properties (union properties):
cimr:hasPartaggregates various containment relations (for example,EquipmentContainer.Equipments,Substation.VoltageLevels). - Transitive closure:
cimr:hasPartTransitiveallows querying parts at any depth. - Property paths:
cimr:connectedToshortcuts the Terminal-ConnectivityNode-Terminal path. - Composite paths:
cimr:connectedThroughPartlinks containers directly if their internal components are connected.
Outcomes
Simplified queries
The complex SPARQL query was reduced to a few readable lines. The LLM can now simply ask for cimr:connectedThroughPart rather than constructing a multi-line property path.
Before (simplified snippet):
?sub (cim:EquipmentContainer.Equipments|
cim:Substation.VoltageLevels|
cim:VoltageLevel.Bays)+
/
cim:ConductingEquipment.Terminals
/
cim:Terminal.ConnectivityNode
/
cim:ConnectivityNode.Terminals
/
cim:Terminal.ConductingEquipment
/
cim:Equipment.EquipmentContainer
?line .
After:
?sub cimr:connectedThroughPart ?line
Performance and efficiency
We created a custom cim.pie ruleset with custom optimizations like transitiveOver and fixed-arity property chains to keep reasoning efficient. The inferred triples increased the knowledge graph size by approximately 1.95x, a manageable expansion that enables significantly easier querying with negligible impact on query speed.
In summary, through semantic reasoning, we can bridge the gap between complex domain ontologies and LLM capabilities. Documenting these inferred properties allows the LLM to discover and use them, thus transforming a prone-to-error SPARQL generation task into a reliable one. If you are interested in getting further into the details of this process, please check out our post Using Semantic Reasoning to Help LLM with SPARQL Generation in Electrical CIM.
Finally, to make Talk2PowerSystem insights actionable for field operations and planning, we had to ground the logical model in physical space.
Mapping electrical resources with GeoSPARQL
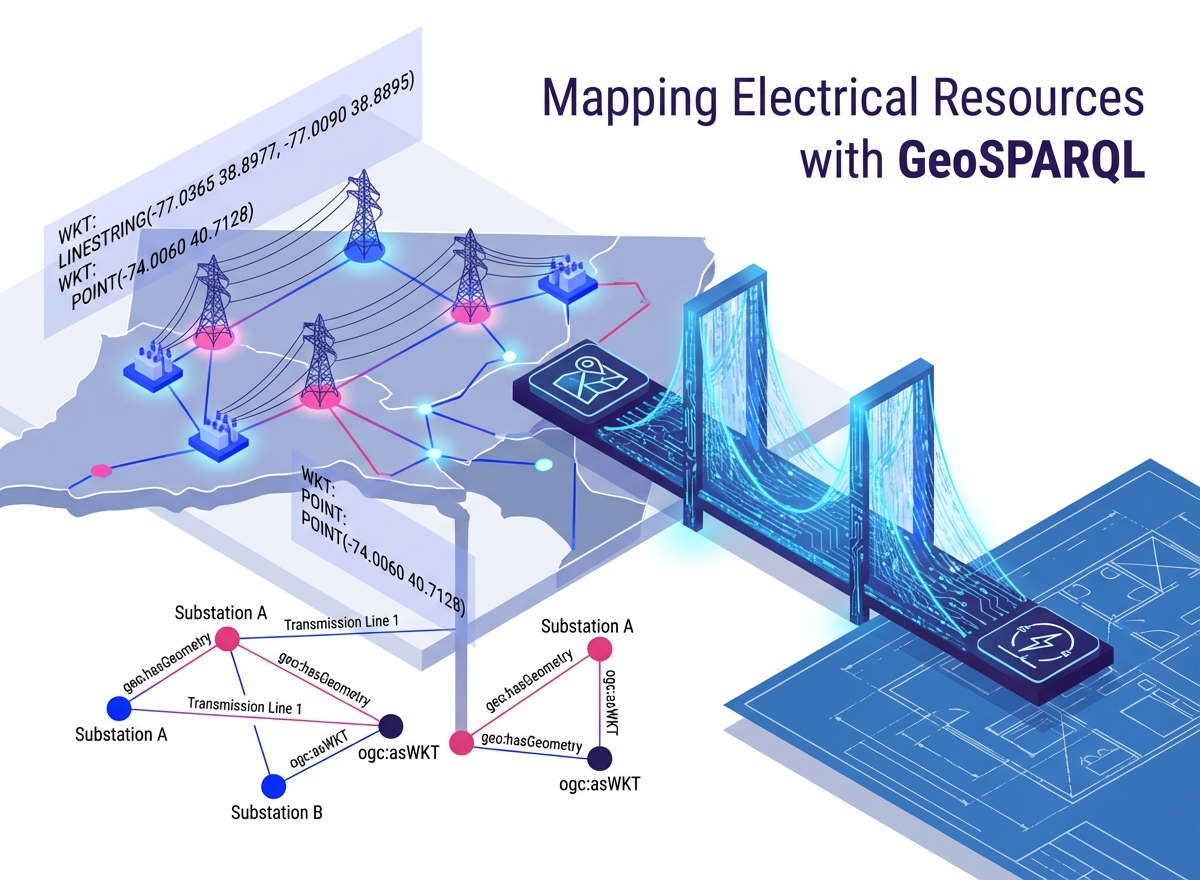
Power systems are inherently spatial: power lines traverse landscapes and substations occupy specific locations. By bridging CIM with geospatial standards, we unlock powerful visualization and analysis capabilities — from simple mapping to complex spatial querying and reasoning.
The Standard: GeoSPARQL
To represent geospatial objects in RDF, we use the GeoSPARQL Ontology. This allows us to map CIM structures directly to standard geospatial types:
- Features:
cim:PowerSystemResourcebecomes also geo:Feature - Geometries:
cim:Locationmaps togeo:Geometry, storing coordinates as Well-Known Text (WKT) literals (for example,POINT,LINESTRING,POLYGON).
This standardization ensures compatibility with the broader ecosystem of geospatial tools and triple stores like Graphwise GraphDB.
Visualization and context
While raw data is useful, visualization provides immediate insight. Since GeoSPARQL is a commonly implemented OGC standard, we can use third-party tools like YasGUI to render query results directly on a map.
Beyond simple plotting, SPARQL queries can dynamically style elements (for example, coloring power lines red or green based on their nominal voltage) and generate rich tooltips for better context.
Spatial querying and integration
The true power of GeoSPARQL lies in querying data based on spatial relationships, not just topological connections.
- Geometric filters: We can query for objects that intersect specific bounding boxes or polygons (for example, “Find all assets within the Sandefjord industrial area”)
- Distance analysis: We can order or filter objects by their distance from a specific point
- Federated queries: We can combine our private grid data with public datasets like OpenStreetMap (via SPARQL federation). This allows us to ask complex questions like “Which power lines cross this specific administrative boundary?” without storing that boundary data ourselves.
In brief, integrating GeoSPARQL with CIM smooths the transition between electrical engineering and GIS. It enables us to enrich power system analytics with geospatial context, leveraging existing standards to visualize, query, and reason about the grid in relation to the real world. If you would like to dig deeper, please check this detailed technical blog: Mapping Electrical Resources with GeoSPARQL.
Conclusion
The Talk2PowerSystem project proves that the future of power systems isn’t just about more data — it’s about more accessible data. By simplifying the vocabulary, creating logical shortcuts through reasoning, and grounding everything in geospatial context, we are empowering the engineers to talk directly to the systems they manage and gather actionable insights.
Do you want to to learn more about the project and our approach to solving such challenges

Details
What is Natural Language Querying?
Natural Language Querying (NLQ) empowers users to interact and “talk” to their data. By using LLMs to bridge the gap between human questions and complex databases, NQL democratizes data access by eliminating the need for specialized query languages.
Learn moreRecommended Content

Practical Approach to Leveraging IoT Data in Energy Sector
Read about Tietoevry Create's collaborative experience with GraphDB and its Talk to Your Graph interface, provided by Graphwise.
Read more
What Is a Knowledge Graph?
Knowledge graphs are a collection of interlinked descriptions of entities that put data into context and enable data analytics & sharing.
Read more
What is Natural Language Querying?
NLQ empowers users to interact and “talk” to their data by using LLMs to bridge the gap between human questions and complex databases.
Read moreFAQ
Any Questions? Look Here
The Common Information Model (CIM) is extremely complex, making it difficult even for experienced engineers to write graph queries manually. Talk2PowerSystem allows them to query power system data using natural language instead.
Large ontologies consume many tokens and can cause LLMs to lose focus. By pruning descriptions, removing administrative metadata, and subsetting to only relevant classes, the team reduced CIM from 900+ classes to 285, significantly improving query accuracy.
CIM's deep nesting requires complex multi-step traversals through many interconnected objects. This makes LLM-generated SPARQL queries prone to being syntactically correct but semantically wrong.
By introducing "shortcut" relations like cimr:connectedThroughPart, complex multi-line queries are reduced to simple readable ones, making reliable LLM query generation possible without altering the underlying data model.
It bridges CIM's logical model with physical space, enabling map-based visualization, spatial filtering, distance analysis, and even federated queries combining private grid data with public datasets like OpenStreetMap.
The knowledge graph grew by approximately 1.95x, which is manageable, and query speed remained largely unaffected at around 0.1 seconds per query.