Unlocking Genetic Insights: How PubMiner AI Enhances ALS Research in HEREDITARY
A case study demonstrating how GraphRAG technology can unlock hidden relationships between genes and neurodegenerative diseases from vast scientific literature.
Healthcare and scientific research generate vast amounts of information, holding great potential to improve disease prevention, diagnosis, and therapeutic approaches. Yet extracting meaningful insights from these diverse knowledge sources remains a challenge.
The project HEREDITARY (HetERogeneous sEmantic Data integratIon for the guT-bRain interplaY) tackles this obstacle by developing an interoperable framework that unifies clinical, genetic, and environmental datasets. This EU-funded initiative brings together 18 organizations across 11 countries to accelerate disease detection, treatment optimization, and knowledge discovery in areas like neurodegenerative and gut microbiome disorders.
Neurodegenerative Diseases: An Integrated Knowledge Approach
One of HEREDITARY’s primary use cases focuses on neurodegenerative conditions that represent some of the most medically complex and costly health challenges globally. Those include Amyotrophic Lateral Sclerosis (ALS), Parkinson’s disease, Alzheimer’s disease, Multiple Sclerosis, Frontotemporal Dementia, and stroke.
At the core of this effort is the development of a comprehensive knowledge graph that captures the relationships between neurodegenerative diseases within the context of genetic, environmental, and clinical data. By implementing advanced forward knowledge engineering, federated analytics, and machine learning workflows, the project identifies new risk factors and treatment responses, paving the way for more precise, knowledge-driven Healthcare.
In this collaborative effort, Graphwise’s PubMiner AI serves as a prototype tool for discovering genetic biomarkers and risk factors. It enables researchers to explore novel gene-disease associations in a knowledge graph, enhancing their understanding of neurodegenerative diseases, particularly ALS.
PubMiner AI In Action: Identifying Genetic Susceptibility and Biomarkers for ALS
PubMiner AI enables the extraction and integration of extensive scientific knowledge from PubMed literature. It builds an evidence-based knowledge graph that includes insights into susceptibility genes and biomarkers for ALS, with potential for uncovering novel findings. PubMiner AI demonstrates how a GraphRAG approach can be applied effectively to answer research questions such as: “What are the potential susceptibility genes and biomarkers for ALS?”
The tool provides a scalable workflow that can be extended in many directions and used as a blueprint for solving similar research problems with answers locked deep in scientific publications.
Benefits of Choosing Databricks as a Hosting Platform
PubMiner AI is hosted on the Databricks Data Intelligence Platform. Databricks provides smooth integration of processing resources on the cloud and enables delivery and management of large data content. It allows efficient management and processing of extensive datasets (such as a portion of the PubMed archive), which makes it an ideal host for PubMiner AI. It also enables prompt interaction with the data even when the database contains millions of records, as is the case with Pubmed.
In addition, users of Databricks can access readily deployed GenAI models such as Llama 3.1-70B-instruct, which facilitates the comparison and model performance (with GPT). For the given use case, Llama 3.1-70B-instruct outperformed GPT-4o and the experiment did not cost any extra deployment efforts other than the pay-per-token fee.
The cost-efficiency and reduced time-to-model are some of the most attractive key features of the platform. Enterprises can use pre-deployed models and if they have sensitive data or want to use the full capacity of a model endpoint, they can also deploy their own model through Mosaic AI Model Serving only with a few clicks.
Another benefit is the managed MLflow service that enables tracking experiments and streamlining the process of finding the best approach for the given task. By providing all this in one place, Databricks is a natural choice for applications where interaction with large databases, GenAI models, and experimentations happen in a single data intelligence platform.
Data Acquisition and Filtering Process
PubMiner AI leverages Graphwise’s LinkedLifeData Inventory (LLDI) with its metadata-rich interlinked datasets. It enables it to identify the most relevant subset of PubMed publications likely containing answers about ALS biomarkers. Key datasets include MeSH, UMLS, NCBI Gene and SemMedDB, which connect directly or indirectly to PubMed, helping retrieve articles related to ALS in the context of diagnosis and related to genetics.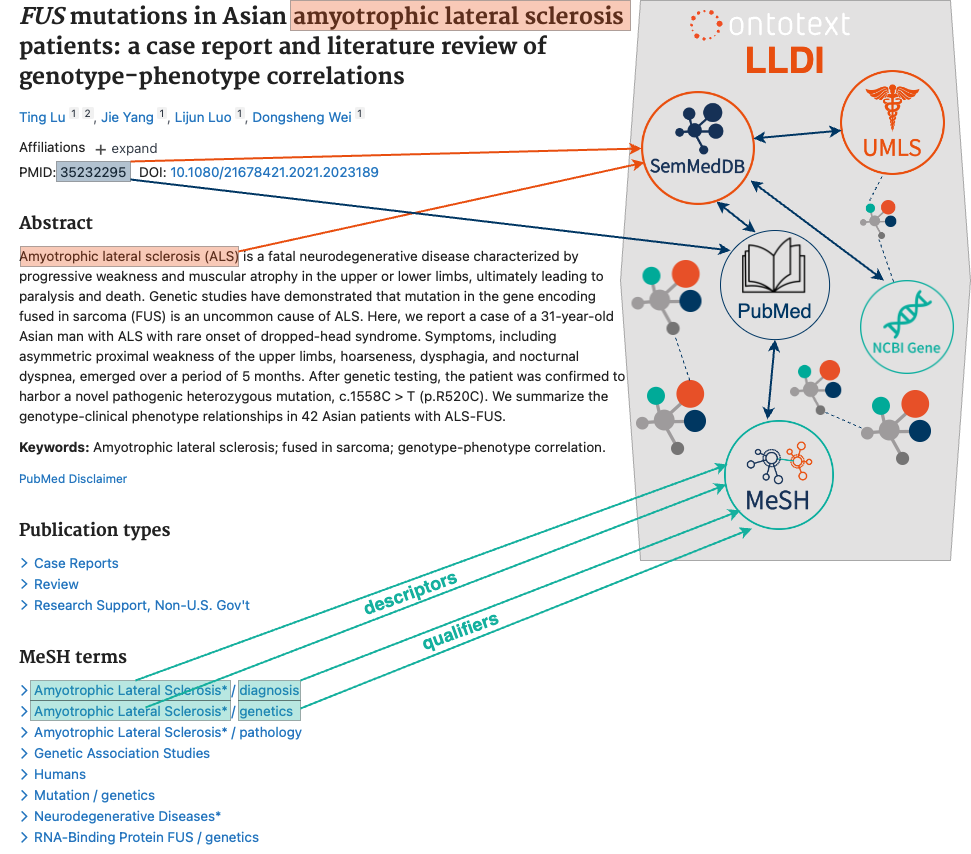
An example of a PubMed resource including the abstract, title and other citation data (on the left), that are annotated by the interlinked datasets available in LLDI (on the right). The links in orange and green demonstrate the available annotations of the article which help for selecting the appropriate documents.
By using the available annotations, narrows the publication scope to a focused set that addresses our central question: “What are the potential susceptibility genes and biomarkers for ALS?”. However, even with refinement, the volume remains significant — 53 publications from the year 2022 alone match this criteria. If the range of publications is wider, for example, for a five-year span, the number of the set of documents will be over hundreds.
To create a scalable approach for handling larger publication sets, we implement Graph RAG technology to identify new ALS susceptibility genes and biomarkers. Each result includes provenance information for verifying its correctness and further exploring the source documents. Subject Matter Expert validation confirms the consistent accuracy of this method.
To demonstrate the Graph RAG approach’s value in extracting novel knowledge, we conducted a comparative analysis. We queried a large language model(LLM) with a general question about known ALS susceptibility genes and biomarkers without providing any context. This yielded a significantly smaller set of genes than our Graph RAG method, as shown in the figure below.
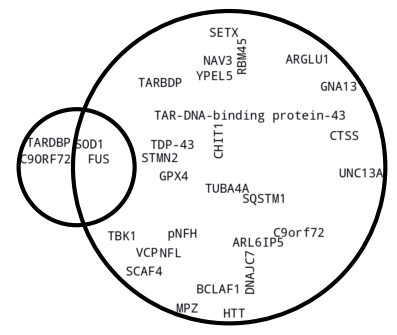
The superiority of the RAG approach when comparing the two result sets, obtained by 1) querying the LLM without context (in the smaller circle on the left), and 2) applying a Graph RAG approach and providing the subset of related documents as a context to the LLM (in the bigger circle on the right).
Knowledge Graph Construction and Exploration
Simple gene name extraction (like “SOD1” or “FUS”) is often not enough as these are just strings. Moving beyond that, PubMiner AI applies the Biomedical Entity Linker, which is an LLDI associated service. It disambiguates these terms and links them to corresponding concepts in the NCBI Gene dataset. This transformation from text strings to knowledge concepts provides access to networks of interlinked resources.
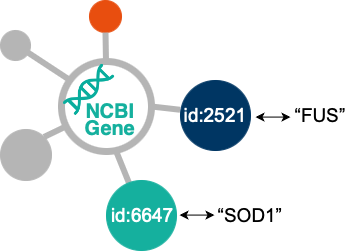
Once the actual gene concepts are available, the system produces a graph that contains the newly extracted knowledge about the relationships between the disease (ALS in our case) and its susceptibility genes. This graph is aligned with a multimodal semantic ontology developed in the HEREDITARY project and it can be loaded into an information system. In this way, it can enrich an existing graph and be used for further exploration of the concepts of interest.
PubMiner AI offers multiple exploration pathways for researchers to investigate beyond initial findings. Users can access LLD Inventory resources, connect to the PubMed portal, and utilize dynamic analytics generated in real-time, allowing data scientists to expand their analysis beyond the original research question.
Accelerating Neurodegenerative Disease Research in HEREDITARY
Accelerating disease detection and treatment planning for neurodegenerative conditions stands as a core objective of the HEREDITARY project. Investigating relationships between susceptibility genes and diseases like ALS represents an area of critical focus within this mission.
PubMiner AI streamlines this research process through a dual approach:
- Providing a structured knowledge extraction workflow that systematically identifies and evaluates genetic relationships
- Enabling efficient integration, verification, and exploration of results through standardized RDF knowledge graphs aligned with the HEREDITARY ontology
This comprehensive approach adheres to the FAIR principles (Findability, Accessibility, Interoperability, and Reusability), ensuring that extracted knowledge becomes a sustainable resource for ongoing research and clinical applications. By transforming complex biomedical literature into structured, interoperable data, PubMiner AI creates pathways for accelerated discovery and verification of potential therapeutic targets.
Wrapping It Up
In this blog post, we have described how PubMiner AI can be utilized for a specific case study. To get acquainted with the methodology applied step by step, you can visit the PubMiner AI notebook. By a free registration you can test this example use case and customize the workflow for answering a question in your domain of interest.

The HEREDITARY project has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement No 101137074. Views and opinions expressed are however those of the author only and do not necessarily reflect those of the European Union. Neither the European Union nor the granting authority can be held responsible for them.
