LinkedLifeData Inventory
Get access to 200+ pre-processed and ready-to-use datasets and ontologies in RDF format about genomics, proteomics, pharmacology and more to enrich your proprietary data, unlock new insights, and accelerate R&D

Graphwise’s LinkedLife Data Inventory (LLDI) empowers you to
Access an extensive data collection from sources like UniProt, ChEMBL, PubMed, and ClinicalTrials.gov, OpenTargets, DisGenet and many more
Cut data operations costs by automating data ingestion and updates
Expedite R&D and the discovery of new therapeutic targets
Bring confidence to your AI with domain knowledge and contextualized data
Enhance insights and innovation by identifying relationships in both structured and unstructured data
Improve regulatory compliance by linking and validating diverse data sources
 Anonymos
Researcher, Leading US biomedical and genomic research center
Anonymos
Researcher, Leading US biomedical and genomic research center
"LinkedLife Data Inventory solution does what they need it to do. The willingness of the Graphwise team to adjust the tool based on needs was a critical point. We formed a relationship with them that made a difference - and our ability to handle large data sets, to find and rank choices is now so much better and faster!"
Who is Graphwise’s LinkedLifeData Inventory for?
Pharma companies
Discover and repurpose a number of existing drugs to treat rare and newly identified diseases.
Biotech companies
Use target data of drug indications and build model datasets.

Research
Navigate efficiently the huge volume and wide range of data about genes, proteins, compounds, diseases, etc.
%
Lower Data Operation Costs
higher adoption across researchers
How it works
Our established FAIRification process ensures the semantic harmonization of the data, normalizing property values to corresponding ontology / terminology instances specific for the biomedical domain.
For datasets serialized in RDF by their official publishers, we generate additional semantic mappings between certain concepts from referential datasets for genes, proteins, drugs, compounds, pathways, diseases, cell types and cell lines.
Whenever necessary for the delivery of a custom knowledge graph solution, we provide a definition of the mappings between the customer proprietary ontology and the incorporated public datasets from our inventory.
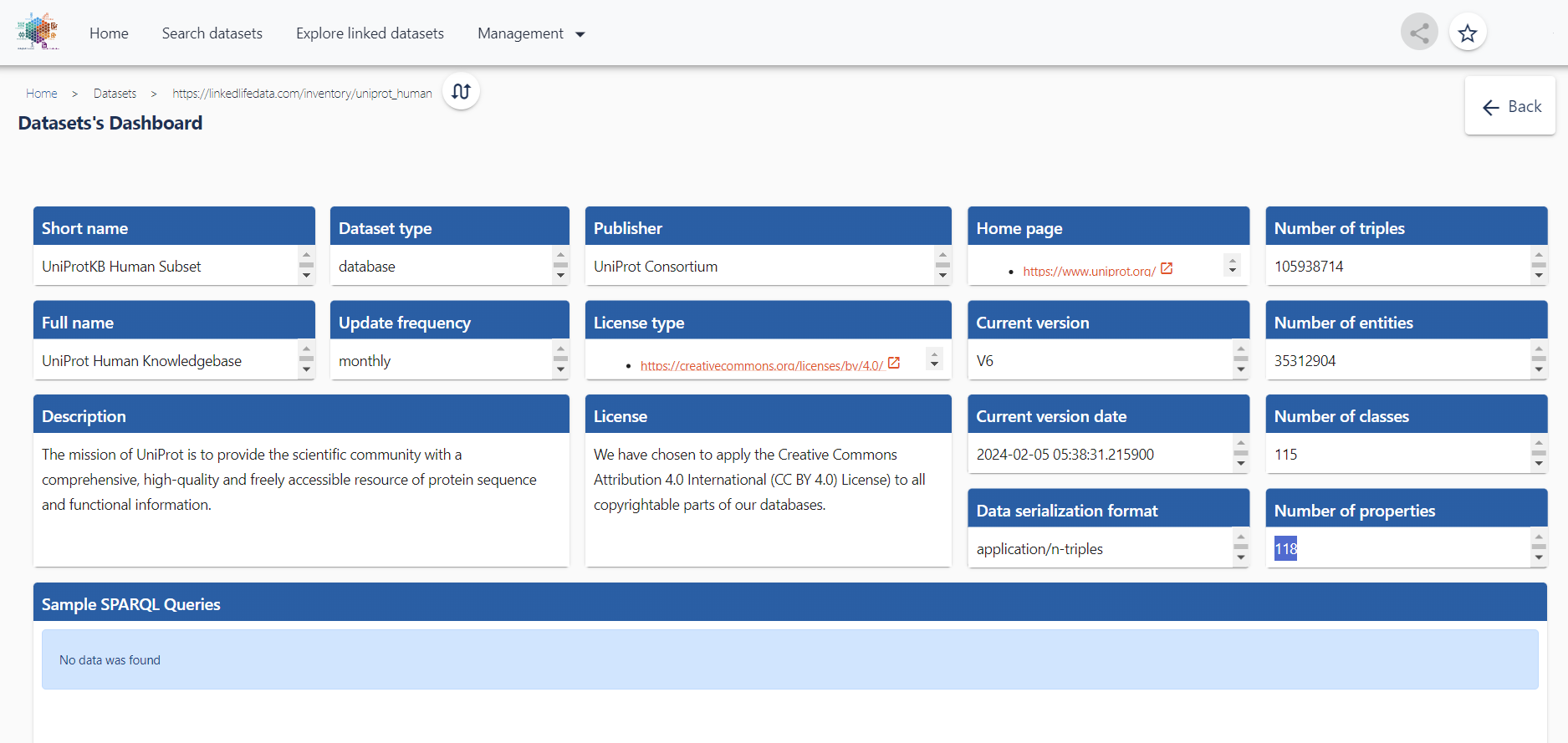
Each single dataset in the inventory is represented by a documented schema and a detailed description of each RDF serialization including classes, properties and semantic mappings.
What to expect?
Find your Dataset
Dive Deeper
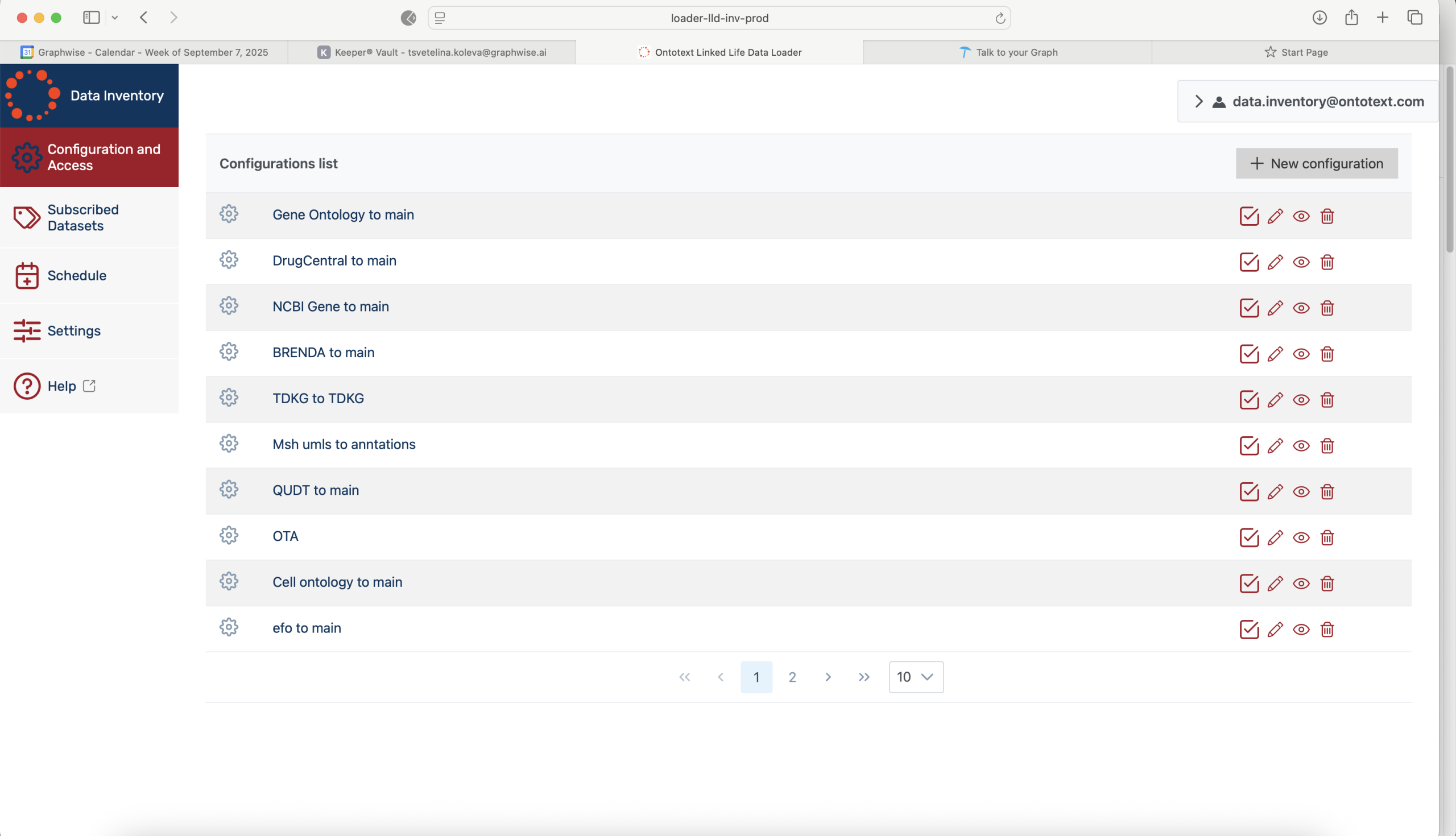
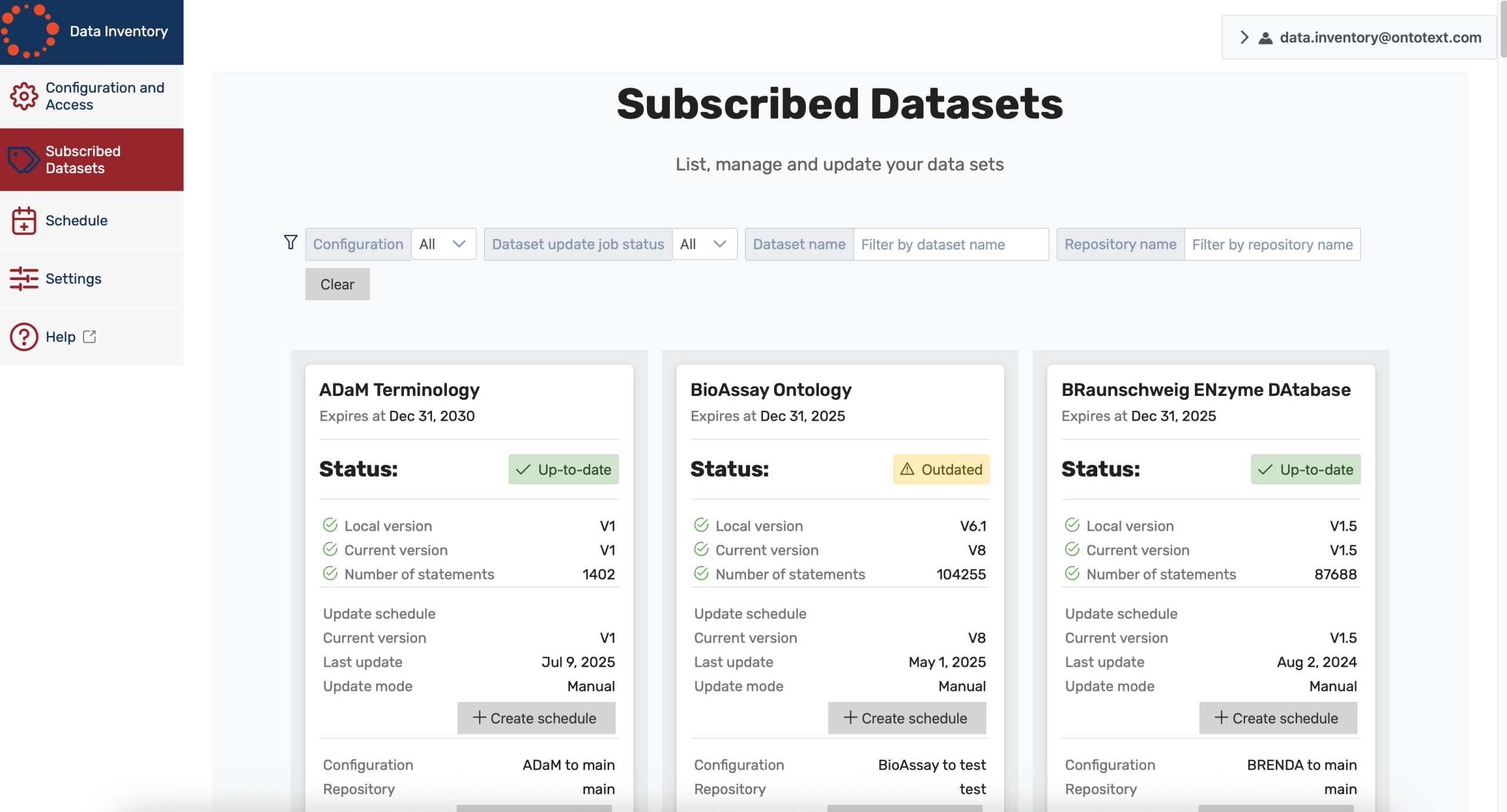
Subscribe to Datasets
Build your Knowledge Graph
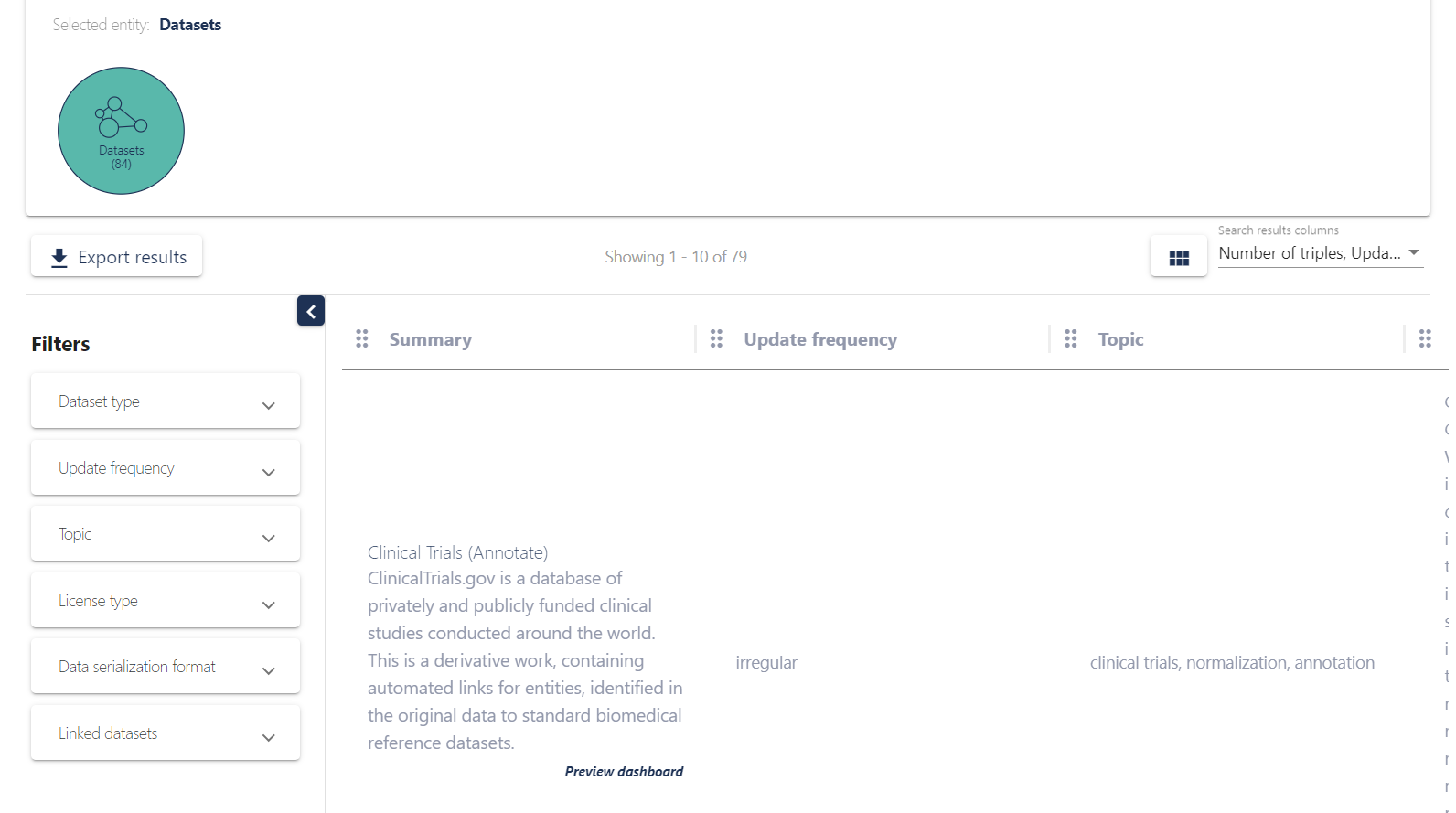
Find your Dataset
You will get access to the LinkeLifeData Catalog system, in which you can identify relevant for your use case data set, using either the search or just filtering the results.
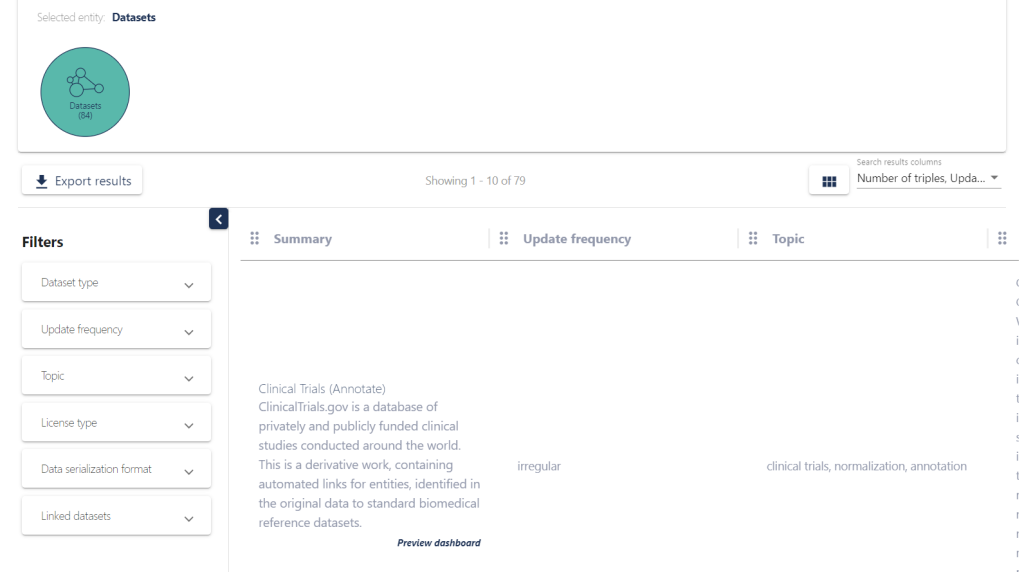
Dive Deeper
Subscribe to Datasets
Build your Knowledge Graph
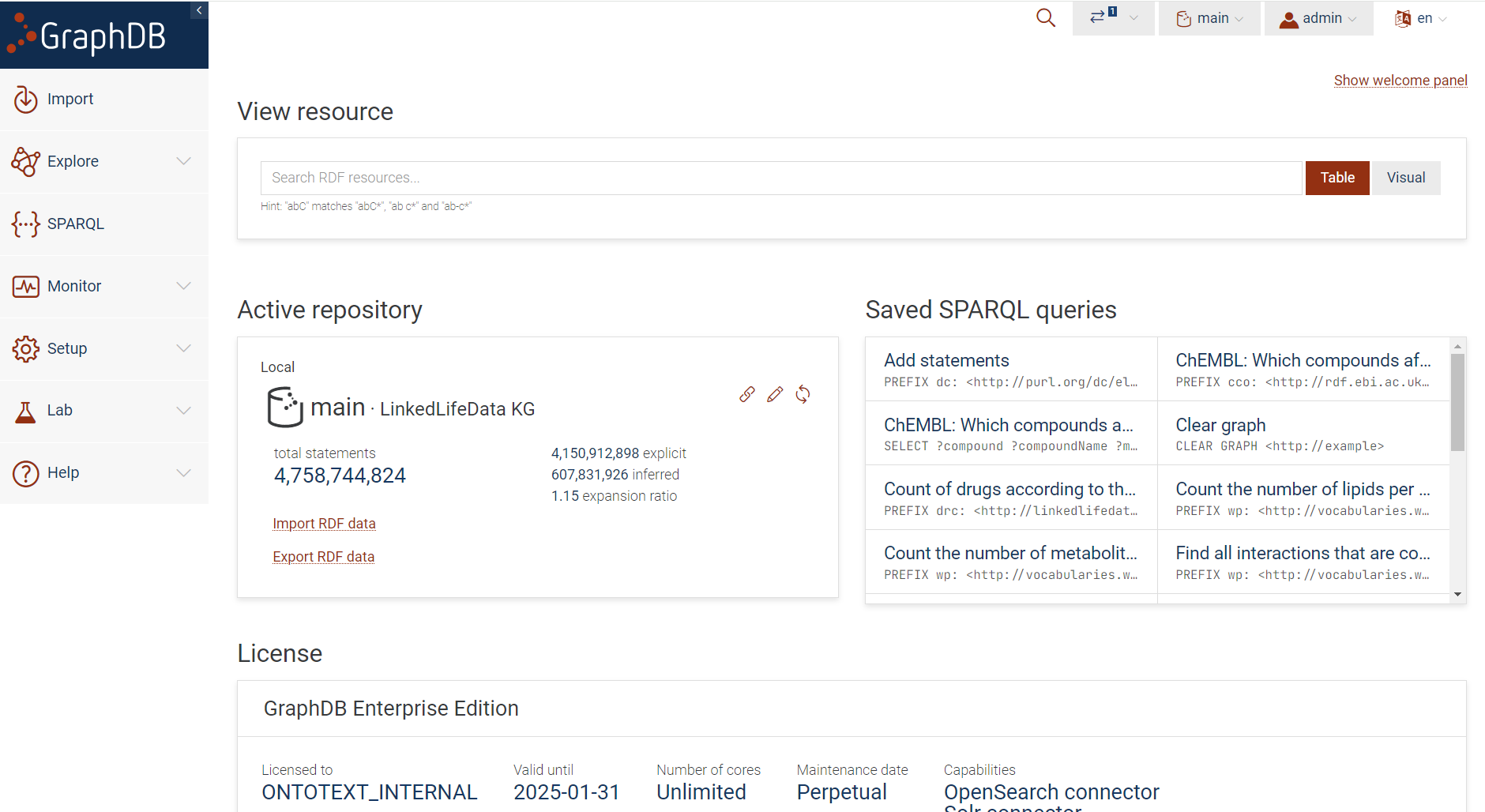
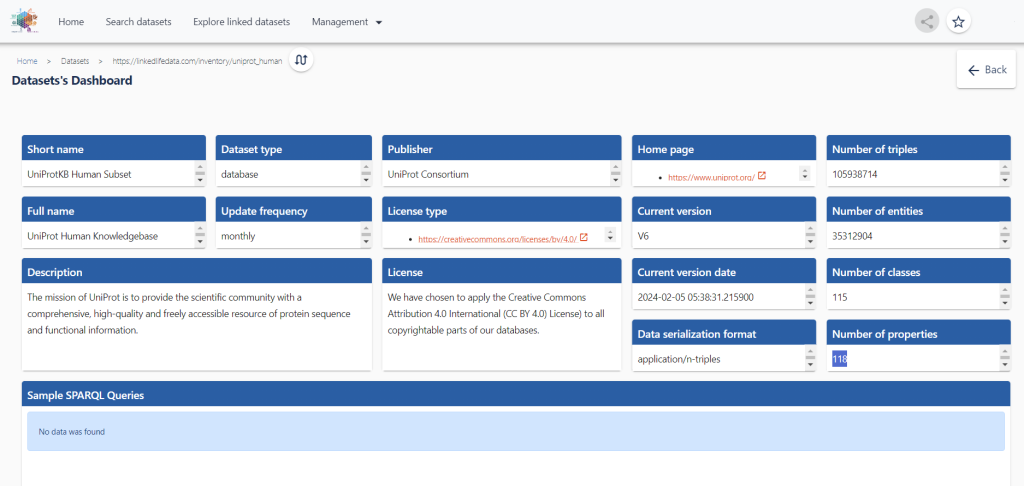
Once you identify the relevant data sets for your use case, you can start building your knowledge graph starting with the source data sets loaded and accessible through GraphDB Workbench
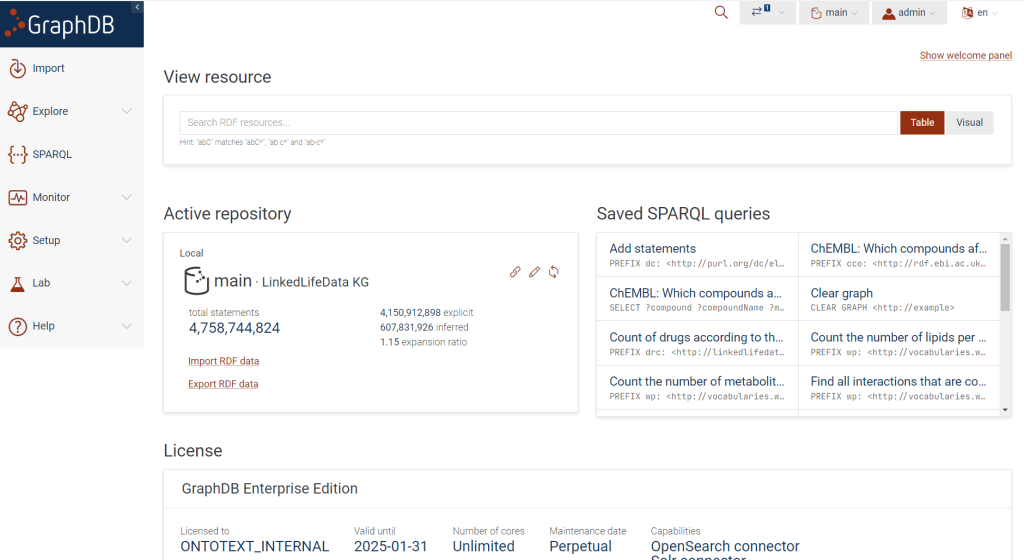
Keep your Knowledge graph up-to-date
Target Discovery – The Underlying Knowledge Graph Solution
AI-powered solution for intelligent target identification and selection helping companies to:
Accelerate drug discovery & clinical research by centralizing biomedical knowledge to discover new hypotheses and facilitate data-driven decision-making
Select the best targets by using customizable analytical methods on various data sources with transparent provenance
Reduce the cost and time for validation through intelligent ranking and prioritization of targets and hits
Faster Drug Discovery
Lower Cost & Time for Target Validation
Talk to LLDI – Powered Target Identification Graph
Knowledge Graphs hold immense potential for scientific discovery, but their complexity, massive scale, and steep technical requirements often make them inaccessible to researchers. Graphwise’s natural language query interface breaks down these barriers, empowering scientists to explore target identification and selection data as easily as asking a question.
This solution makes complex data accessible, visual, and actionable for every researcher.
Key Challenges
Complex and evolving schemas – The Knowledge Graphs structure can be hard to navigate and understand
Specialized skills required – Graph query languages are often unfamiliar to most researchers
Fragmented tools – Limited, inconsistent options for visualization and analysis
Overwhelming scale – Billions of connections make queries slow and results hard to digest
Difficult to interpret – Dense, interconnected results often need advanced summarization
How it helps
Accessible for all – Query in natural language, no coding
Faster insights – Get answers instantly, no need for specialists
Stronger ROI – Maximize value of your KG investment

Key benefits
Accelerate drug discovery and clinical research by 10x
Select the best targets
Reduce the cost and time for validation by 5x
Related Resources
Blog

Learn how Graph RAG technology can unlock hidden relationships between genes and neurodegenerative diseases from vast scientific literature.
LEAFLET

PubMiner AI, based on LinkedLife Data Inventory, helps overcome the challenges in automatic knowledge extraction from large volumes of scientific publications.