Building Smarter, Faster — How GraphRAG Cuts AI Development Costs and Complexity
Enterprise AI investment continues to grow — but so do the costs and complexity of building and running these systems. Learn how GraphRAG simplifies AI systems while reducing build, maintenance, and operational costs.
Main Takeaways
- Traditional RAG breaks down at scale — what gets AI to production fast eventually creates fragmented pipelines, rising token costs, and maintenance overhead that's hard to control.
- GraphRAG replaces pipelines with a shared knowledge layer — instead of duplicating indexes per use case, one reusable graph serves multiple AI applications, cutting sprawl and engineering effort.
- Structured retrieval directly lowers LLM costs — by surfacing only relevant context rather than broad chunks, GraphRAG can reduce token usage by up to 80%.
Once AI moves into production, cost predictability and operational control quickly become critical concerns. AI systems rely on multiple components, including graphical processing units (GPUs), data pipelines, retrieval layers, and external APIs. This makes it difficult to forecast, spend, or control long-term operational costs. As a result, 85% of organizations miss AI cost forecasts by more than 10%, largely due to limited visibility and infrastructure complexity.
To address this, many teams adopted retrieval-augmented generation (RAG). RAG simplified early AI deployments by grounding models in external data and reducing retraining, helping teams ship AI features faster.
However, as RAG systems scale, new challenges emerge. Fragmented retrieval layers, repeated indexing, and growing operational overhead make systems harder to maintain and control. The challenge isn’t just building AI, but building RAG-based systems that scale sustainably.
Graphwise’s GraphRAG addresses these limitations with a graph-based approach that reuses existing data structures, reduces redundant retrieval and retraining, and lowers operational overhead. This leads to faster deployment, lower maintenance, and more predictable delivery while maintaining performance.
This article explores why traditional RAG becomes costly at scale and how GraphRAG offers a more sustainable path forward.
How traditional RAG simplified early AI deployments
Enterprise AI development has long been constrained by high costs and architectural complexity. AI systems required significant compute resources, extensive data preparation, and deep integration with existing enterprise systems, all of which slowed deployment and inflated budgets. Traditional RAG helped reduce these barriers and made AI more accessible.
Here’s how traditional RAG simplified the complexities of early AI development.
Infrastructure and compute costs
Many early AI systems ran across fragmented environments. Today, 61% of enterprises operate AI workloads in hybrid setups, which makes cost management more difficult. At the same time, compute requirements kept increasing. Since 2016, compute costs for large AI models have grown roughly 2.4x per year.
Traditional RAG helped control this by reducing the need to retrain models every time enterprise data changed. Instead, systems could retrieve relevant information at query time, lowering compute usage and making early deployments more affordable.
Data preparation complexity
Data preparation has historically taken up most of an AI project’s timeline. Teams spend a large part of their effort cleaning, labeling, and integrating data before systems can deliver any real value. This process often consumes a significant share of both time and cost.
Traditional RAG simplified this process by allowing teams to work directly with existing documents and knowledge repositories. This reduced upfront data transformation and accelerated the path from experimentation to usable AI applications.
Integration with legacy systems
Integrating AI with legacy applications, databases, and workflows has been another major hurdle. 67% of organizations report significant challenges integrating AI with legacy systems — with integration efforts increasing project costs by an average of 82%.
Traditional RAG lowered integration friction by layering retrieval over existing systems rather than replacing them. This lets AI augment current workflows with minimal disruption.
The limitations of traditional RAG architectures
Traditional RAG helped organizations get AI into production faster. But as use cases expanded and systems grew, RAG’s limitations became harder to ignore. What worked well for early deployments often struggled under real-world scale and complexity.
Some of the limitations include:
- Frequent re-indexing and embedding rebuilds — Text-only or vector-based RAG systems rely on embeddings that must be rebuilt whenever data changes. As datasets grow or update frequently, this creates ongoing maintenance work and slows iteration.
- Inefficient retrieval and rising LLM costs — Traditional RAG typically retrieves large chunks of loosely related content. This broad retrieval increases prompt size, drives up token usage, and slows response times — making costs harder to predict at scale.
- Growing architectural sprawl — Each new AI use case often comes with its own pipelines and vector indexes. Over time, teams end up maintaining multiple parallel systems. This increases maintenance effort and makes the overall setup harder to manage.
- Limited understanding of context and relationships — Vector similarity alone struggles to capture how pieces of information relate to one another. In complex domains, this leads to shallow context, inconsistent answers, and more manual validation.
Graphwise GraphRAG: A reusable, grounded RAG architecture
As AI systems scale, teams need retrieval approaches that reduce time spent searching, reworking data, and managing fragile pipelines. Research shows that unstructured retrieval approaches demonstrate significantly lower efficiency and accuracy compared to graph-based retrieval in complex QA tasks. Graphwise’s GraphRAG is designed around this principle.
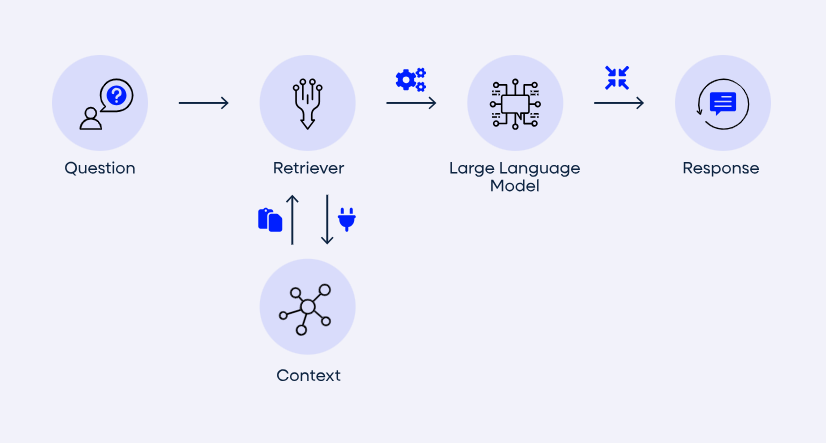
GraphRAG combines knowledge graphs with large language models to clearly separate knowledge modeling from language generation. Instead of relying only on document chunks or vector similarity, GraphRAG represents enterprise knowledge as connected entities and relationships. These relationships guide retrieval, allowing the system to surface precise, context-aware information rather than broad sets of loosely related text.
This structured approach changes how users interact with information. Queries can move directly through connected concepts, making it easier to surface summarized facts and grounded answers — even in complex enterprise environments.
GraphRAG introduces several architectural advantages over traditional RAG approaches:
- Reusable knowledge foundation — Knowledge is captured in a shared graph and reused across multiple AI applications and assistants.
- Simpler updates and evolution — Changes happen at the graph level, without retraining models or rebuilding embeddings when data evolves.
- Reduced system sprawl — A shared knowledge layer replaces duplicated pipelines, indexes, and retrieval logic.
- More controlled retrieval — Structured relationships help limit context to what’s actually relevant, improving efficiency and grounding.
GraphRAG vs. traditional RAG
Traditional RAG and GraphRAG handle complexity and scale differently in the following ways:
| Capability | Traditional RAG | Graphwise GraphRAG |
|---|---|---|
| Development cycles | Faster to start, harder to scale | Slightly more upfront modeling, faster reuse |
| Maintenance and lifecycle | Frequent re-embedding and pipeline upkeep | Centralized updates at the graph level |
| LLM usage efficiency | Broad retrieval increases token usage | Structured retrieval limits unnecessary context |
| Accuracy | Varies with chunking and vector similarity; May struggle with complex or multi-hop questions | Consistent accuracy through explicit entity relationships and grounded retrieval |
| Scalability | It may become harder to manage as data sources and use cases grow | Designed to scale AI by reusing a shared knowledge graph across applications |
| Cost predictability | Costs fluctuate as systems expand | More stable, controlled architecture |
How GraphRAG reduces AI development and operational costs
GraphRAG streamlines AI development and operations by leveraging a reusable, graph-based architecture. It helps teams deliver AI faster, maintain less, and scale more effectively.

- Teams can build new AI applications on previously modeled knowledge, which reduces repeated engineering effort and accelerates development.
- Changes to data or business rules happen directly in the graph, avoiding full pipeline rebuilds or costly retraining cycles.
- Only the most relevant context is retrieved, which lowers token usage, reduces inference costs, and improves response efficiency.
- Grounded retrieval minimizes hallucinations and cuts down on redundant validation, ensuring outputs are trustworthy.
- Relationships and insights captured once in the graph can be applied to multiple AI applications. This capability helps reduce duplication and simplify scaling AI use cases.
With these capabilities, GraphRAG reduces development and operational overhead. It also provides a foundation for more predictable and cost-effective AI adoption.
GraphRAG ROI: Faster development and lower maintenance
Graphwise GraphRAG delivers measurable improvements in AI development speed, operational efficiency, and cost predictability.
- Faster build time — Teams can move nearly 2.7x faster, with searches running 40% quicker and over 30 minutes saved per query. This significantly accelerates development cycles.
- Lower maintenance hours — Manual tagging is cut by 60%, while duplicate and redundant work drops by 50%, so teams can focus on higher-value tasks.
- Predictable delivery — Targeted retrieval reduces LLM token usage by up to 80%, helping organizations keep project timelines and budgets under control.
Conclusion
AI development becomes expensive when systems grow fragmented and difficult to maintain. While traditional architectures helped teams get started, they often introduce long-term complexity — rising operational costs and unpredictable delivery timelines.
Graphwise GraphRAG offers a more sustainable path forward. It simplifies development, reduces maintenance effort, and lowers ongoing LLM usage by grounding AI systems in reusable knowledge graphs. Teams can build once, reuse knowledge across use cases, and scale AI without constant rework.
The result is smarter AI delivered faster, with costs easier to control and outcomes easier to trust.
Want to learn how Graphwise GraphRAG enables scalable, enterprise-ready AI architectures?

Details
What is GraphRAG
Retrieval Augmented Generation or RAG enhances LLMs with external knowledge for more accurate, contextual question answering. See how RAG can evolve into GraphRAG, which uses knowledge graphs as a source of context or factual information.
Learn moreRecommended Content

Accelerating Discovery — How GraphRAG Drives ROI in R&D and Knowledge-Intensive Workflows
Read about how GraphRAG helps organizations cut search time, speed up discovery, and turn AI pilots into measurable ROI.
Read more
Bring Your Enterprise Information Security Management System with GraphRAG to the Next Level
Read abou how GraphRAG systems enhance enterprise information security management by using knowledge graphs
Read more
From Data to Decisions — How GraphRAG Accelerates Time to Insight and Boosts ROI
Read about how GraphRAG connects data, context, and meaning to deliver faster and verifiable insights that accelerate decision-making and boosts ROI
Read more
GeoAI: How GraphRAG Unlocks Complex Geospatial Knowledge
Read about how LLMs struggle with spatial queries, but connecting them to structured geographic knowledge graphs through GraphRAG improves accuracy.
Read more
AI-ready Graph Environments: The Key to Scaling AI with Graphwise’s Knowledge Graphs
Read about why most enterprise AI fails and how Graphwise creates graph environments using knowledge graphs and semantics.
Read more
Graph Technologies and Graph RAG: Shaping the Future of Corporate Knowledge Management
Read about how recent studies reveal the potential of graph technologies and GraphRAG to enable organizations to manage data more effectively
Read moreFAQ
Any Questions? Look Here
AI projects frequently exceed budgets and miss cost forecasts primarily due to the "Bad Data Tax," where organizations are forced to spend 40% to 60% of their IT resources cleaning and integrating fragmented, siloed, and low-quality Data that was not initially prepared for AI readiness. This massive technical hurdle is often compounded by a significant "skills gap" in specialized expertise and the inherent difficulty of scaling proof-of-concept models into production-ready systems, which leads to a severe underestimation of the infrastructure and ongoing maintenance costs required. Furthermore, shifting business priorities during long development cycles and overhyped initial expectations often result in projects that lack clear ROI, requiring expensive, unplanned efforts to ground models in business context and ensure they deliver reliable results.
At scale, traditional vector-based Retrieval-Augmented Generation (RAG) faces significant limitations, primarily centered on performance degradation, high operational costs, and a lack of semantic depth. As data complexity grows, these systems often struggle with "low recall"—where information spread across multiple chunks leads to incomplete answers—and an inability to perform multi-hop reasoning because they cannot trace relationships between entities across documents. Furthermore, the structural over-simplification of encoding complex documents into single dense vectors causes the loss of fine-grained nuances, while the need for frequent, costly re-indexing in dynamic environments creates a heavy maintenance burden. These factors often result in high latency and increased hallucinations, making standard RAG architectures difficult to scale for high-precision, enterprise-grade applications without integrating more structured approaches like knowledge graphs.
GraphRAG significantly reduces LLM token usage by replacing the retrieval of large, unprocessed text chunks with a highly selective process that provides the model with precise, context-rich structured data from a semantic knowledge graph. By shifting much of the reasoning and relationship-mapping workload into the graph itself, GraphRAG can identify the most relevant entities and hierarchical summaries—such as "root-level community summaries"—resulting in up to an 80% reduction in token consumption compared to conventional RAG methods. This targeted approach ensures that only the essential information needed to answer a specific query is fed into the LLM, directly lowering operational costs while maintaining high factual accuracy.
GraphRAG delivers a significantly higher ROI than traditional RAG by transforming AI from a prototype expense into a strategic value driver, offering up to a 3x return on investment. While traditional RAG often struggles with accuracy (averaging 60%), GraphRAG leverages structured knowledge graphs to achieve over 90% accuracy, reducing costly "human-in-the-loop" error corrections and cutting implementation and maintenance costs by up to 70%. Additionally, GraphRAG optimizes operational expenses with up to an 80% reduction in token usage and provides 15-20% efficiency gains in knowledge work, enabling nearly threefold faster time-to-action compared to traditional vector-based systems.
Knowledge graphs improve AI accuracy and reduce hallucinations by providing a structured, verified "source of truth" that grounds Large Language Models (LLMs) in reliable, domain-specific data. Unlike standalone LLMs that predict the next word based on statistical patterns, Knowledge graphs represent information as a network of explicit entities and relationships, offering the essential context and semantic logic required for precise reasoning. By leveraging architectures like Graph Retrieval-Augmented Generation (GraphRAG), AI systems can anchor their responses to traceable, factual evidence rather than relying solely on internal weights. This symbolic grounding ensures that AI outputs are not only factually accurate and verifiable but also transparent, effectively bridging the gap between statistical probability and structured knowledge to curb the generation of false or unfounded information.
To scale RAG systems without a proportional rise in maintenance costs, transition from traditional vector-only architectures to Graph RAG (Semantic RAG), which can reduce implementation and maintenance overhead by up to 70%. Unlike vector databases that suffer from "re-indexing fatigue" and require manual chunking as data grows, knowledge graphs utilize a structured taxonomy to enable automatic, incremental updates and precise, context-aware retrieval. By offloading complex tasks like entity linking and multi-hop reasoning to the graph and reserving LLMs strictly for final answer generation, organizations significantly lower token consumption and minimize the need for manual "human-in-the-loop" corrections. This architectural shift replaces fragile, code-heavy pipelines with a governed semantic layer, ensuring that system accuracy remains high and operational expenses remain stable even as data volume and complexity expand.