From Retrieval to Reasoning: Enhancing HippoRAG with Graph-Based Semantics
How an ontology-based knowledge graph boosts the multi-hop Q&A accuracy of one of the leading schemaless GraphRAG systems
Main Takeaways
- Vector RAG has tunnel vision — it finds text similar to the query but can't connect dots across distant documents, making it unreliable for questions that require chaining multiple facts.
- HippoRAG mimics human memory but still lacks a world view — its associative graph is built from loose co-occurrence, not domain logic, so the connections it traverses are noisy and unreliable.
- An ontology turns association into reasoning — replacing loose entity extraction with a structured schema gives the PageRank algorithm a clean highway to travel, pushing accuracy from 86% to 95% on complex questions.
- The real breakthrough is switching between reading and calculating — unlike standard RAG, Semantic GraphRAG can answer "how many genes are linked to ALS?" with a SPARQL query, not an LLM guess.
Retrieval Augmented Generation (RAG) has become the standard for grounding large language models (LLMs) in proprietary data. However, as we push RAG systems into more complex domains, we also see the limitations of such solutions.
Standard RAG relies heavily on vector similarity search. While efficient, it suffers from a fundamental “tunnel vision”: it retrieves chunks based on semantic proximity to the query, but often fails to “connect the dots” across disjointed pieces of information. It struggles with multi-hop reasoning, where the answer lies in the relationship between two distant documents, not in the documents most similar to the initial question.
Enter GraphRAG, and specifically HippoRAG 2 (Hippocampal Retrieval-Augmented Generation). These systems attempt to solve this challenge by structuring data as a graph, allowing retrieval based on relationships rather than just surface-level similarity. HippoRAG takes this a step further by mimicking the neurobiological processes of human long-term memory to create additional associative links. The latter is the major difference to most of the popular GraphRAG implementations, which derive schemaless knowledge graphs from documents.
However, even HippoRAG has a limitation: it typically builds its graph based on simple co-occurrence or open information extraction. It lacks a true “world view”. It also still relies on semantic similarity to manage to traverse the relations it has found in the data properly.
In this post, we explore how to supercharge the graph-based retrieval process by injecting a semantic backbone. We will demonstrate how replacing generic graph construction with strict ontologies and structured knowledge graphs transforms HippoRAG from an associative engine into a reasoning engine.
How does HippoRAG work
To understand how we improved the system, we first need to understand the unique architecture of HippoRAG.
Unlike standard GraphRAG approaches that might simply traverse a knowledge graph, HippoRAG is inspired by the Hippocampal Indexing Theory of human memory. In the human brain, the Neocortex stores actual memories (analogous to LLM parameters and a document corpus), while the Hippocampus acts as a dynamic index, storing the pointers and associative relationships between those memories.
HippoRAG replicates this duality to enable faster, multi-hop retrieval. It operates in two distinct phases:
1. Offline indexing (the associative graph)
In the standard implementation, HippoRAG processes the document corpus to create a schemaless graph.
- Extraction: It uses an LLM (or OpenIE) to identify key noun phrases and entities within the documents.
- Graph construction: It builds a knowledge graph where nodes are these extracted entities. Edges are created based on co-occurrence (two entities appearing in the same passage) or strong semantic similarity.
- Result: A massive associative map where Document A is linked to Document B because they share the entity “Python,” even if the documents never explicitly reference each other.
2. Online retrieval (the neurobiological pattern)
When a user asks a query, HippoRAG doesn’t just look for keywords; it simulates a neural activation process.
- Vector search on triples: The system does a vector search based on the query to find the triples with the biggest vector similarity to the query.
- Node activation: These entities are located in the graph and are selected as the starting point for Personalized PageRank.
- Personalized PageRank: This is the core mathematical engine. The system uses the Personalized PageRank algorithm to spread this activation across the graph, in a manner similar to the priming in the human brain. By using the nodes with the highest vector similarity, it traverses the graph to find the most relevant documents.
- Ranking: The system identifies which documents are most strongly connected to the highly activated nodes in the graph and retrieves them.
Key insight:
Because the activation spreads through the graph, HippoRAG can find a document that contains none of the query words, provided it is strongly linked to the query through a chain of intermediate entities. This is the essence of multi-hop retrieval.
However, the “Vanilla” HippoRAG relies on the LLM to hallucinate the connections or extract them loosely. By replacing this loose association with a rigorous ontology and a knowledge graph, we provide the PageRank algorithm with a much cleaner, noise-free highway to travel on.
Extending HippoRAG with an ontology and a knowledge graph
To transform HippoRAG from an associative engine into a reasoning one, we extended the pipeline by injecting a structured “spine”: an automatically generated ontology and a knowledge graph. This moves us away from loose, probability-based connections to explicit, logic-based relationships.
1. Ontology creation
The first step is moving from chaos to order. Instead of ingesting raw triples immediately, we iterate over the relations initially extracted by HippoRAG. We employ an LLM agent that acts as a schema architect. At each step, this agent reviews a batch of extracted relations alongside the ontology built so far. Guided by a user-defined goal, the agent infers necessary classes and relations, deciding iteratively how the world should be structured. This ensures the ontology isn’t just a list of words, but a coherent framework tailored to the specific domain.
2. Knowledge graph creation
Once the ontology provides the scaffolding, we populate the building. A second LLM agent iterates over the documents to extract a strict knowledge graph that conforms to our new ontology. To ensure data integrity, a dedicated “repair agent” follows behind, fixing syntax errors, and ensuring compliance.
Crucially, we also build an Inverted Index. In standard graph systems, you might know that “John knows Jane,” but you lose the context of how. The inverted index links every entity and triple in the knowledge graph back to the exact source text.
- Without the index: The graph knows
(John, knows, Jane). - With the index: The system can trace the
knowsrelation back to the paragraph describing “John met Jane at a jazz bar in Chicago.” This turns the knowledge graph from a simple fact store into a navigational map that points back to the rich nuance of the original documents.
3. Inference
We split the inference process into two synergistic retrieval steps:
- Associative Retrieval: We utilize HippoRAG’s Personalized PageRank to identify documents based on network proximity and activation.
- Structured Retrieval: Simultaneously, we perform SPARQL queries against the knowledge graph. To jumpstart this, we provide the model with a list of relevant triples, helping it anchor its search within the graph.
The outputs from both streams — the document context from HippoRAG and the structured facts from the knowledge graph — are fed into a final synthesis agent. This agent combines the “associative” and the “logical” to answer the user’s query. A visualization of the inference pipeline can be explored in Figure 2.
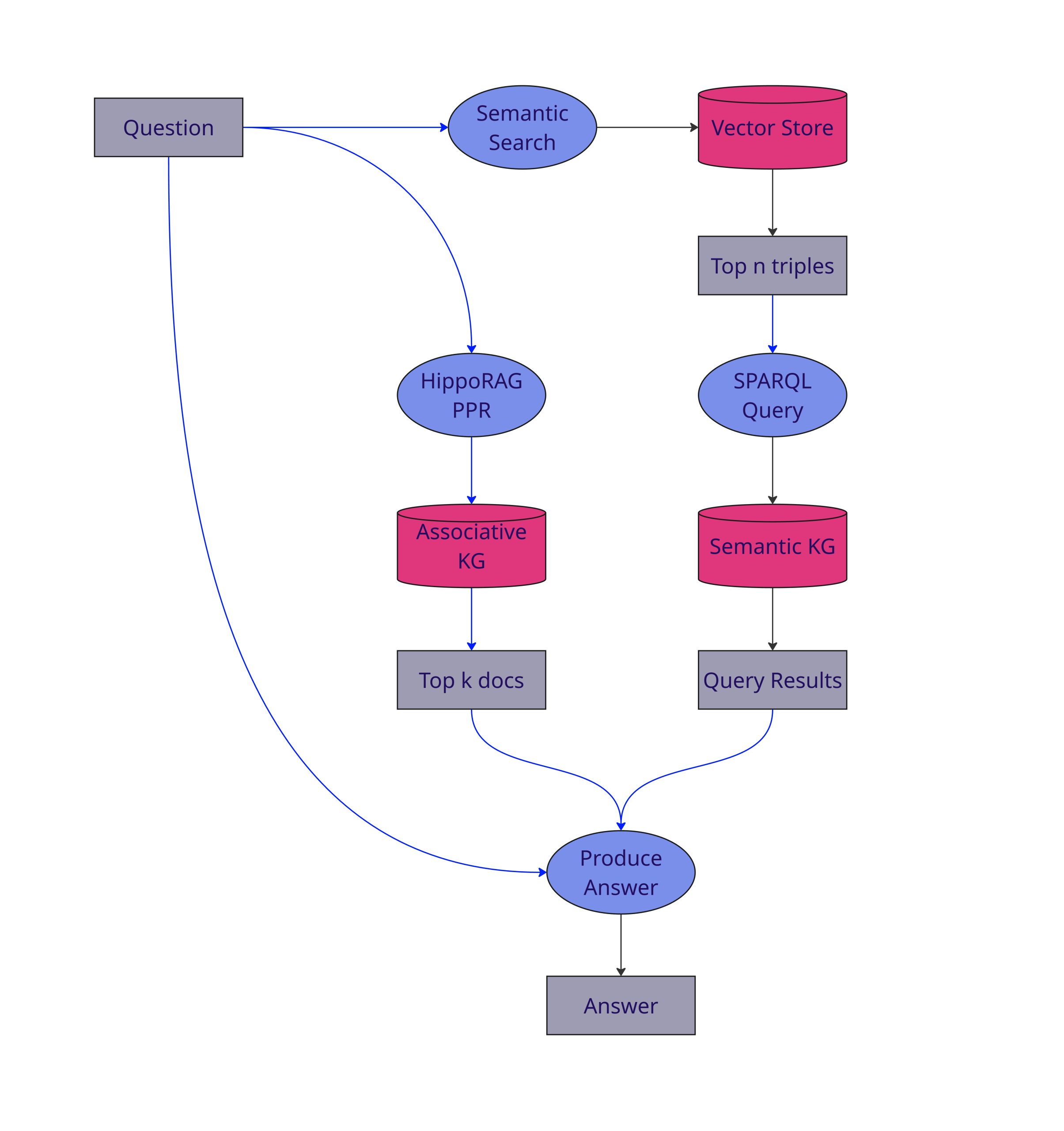
Evaluation and results
To test the efficacy of this semantic backbone, we turn to MuSiQue, widely considered the most complex multi-hop reasoning dataset available. MuSiQue requires a system to successfully navigate 2 to 4 distinct “hops” of information to arrive at an answer. For example, a 3-hop question could look something like “In which country was the director of the film ‘The Great Gatsby’ born?”
We avoided standard “exact match” metrics, which often penalize correct but verbose answers. Instead, we employed an LLM-as-a-judge evaluation protocol that assesses whether the answer is accurate and contains the necessary information, regardless of phrasing.
The majority of questions in MuSiQue are 2-hop. For that reason, we separated evaluations into one evaluation on 2-hop only questions and one evaluation on equal parts 2, 3 and 4 hop questions. For each evaluation, we took a random subset of 100 MuSiQue questions. Manual examination of the questions, however, revealed significant issues with the question spanning from incorrect answers to impossible connections. To filter out these unanswerable questions, we ran a system with exact context three times on each question and if it never produced the expected response the question was removed. The results presented below are based on the accuracy over the remaining answerable questions.
Performance on 2-hop questions
As seen in the results below, adding an ontology-based knowledge graph yields immediate dividends. Semantic GraphRAG manages to answer about 95% of answerable questions, creating a clear separation from standard HippoRAG (86%) and a massive improvement over traditional Vector RAG (79%). The “LLM w/o RAG” category (71%) is also included to demonstrate the ability of LLMs to answer these questions with general world knowledge- something only possible because MuSiQue is a public dataset and therefore part of their training corpora.
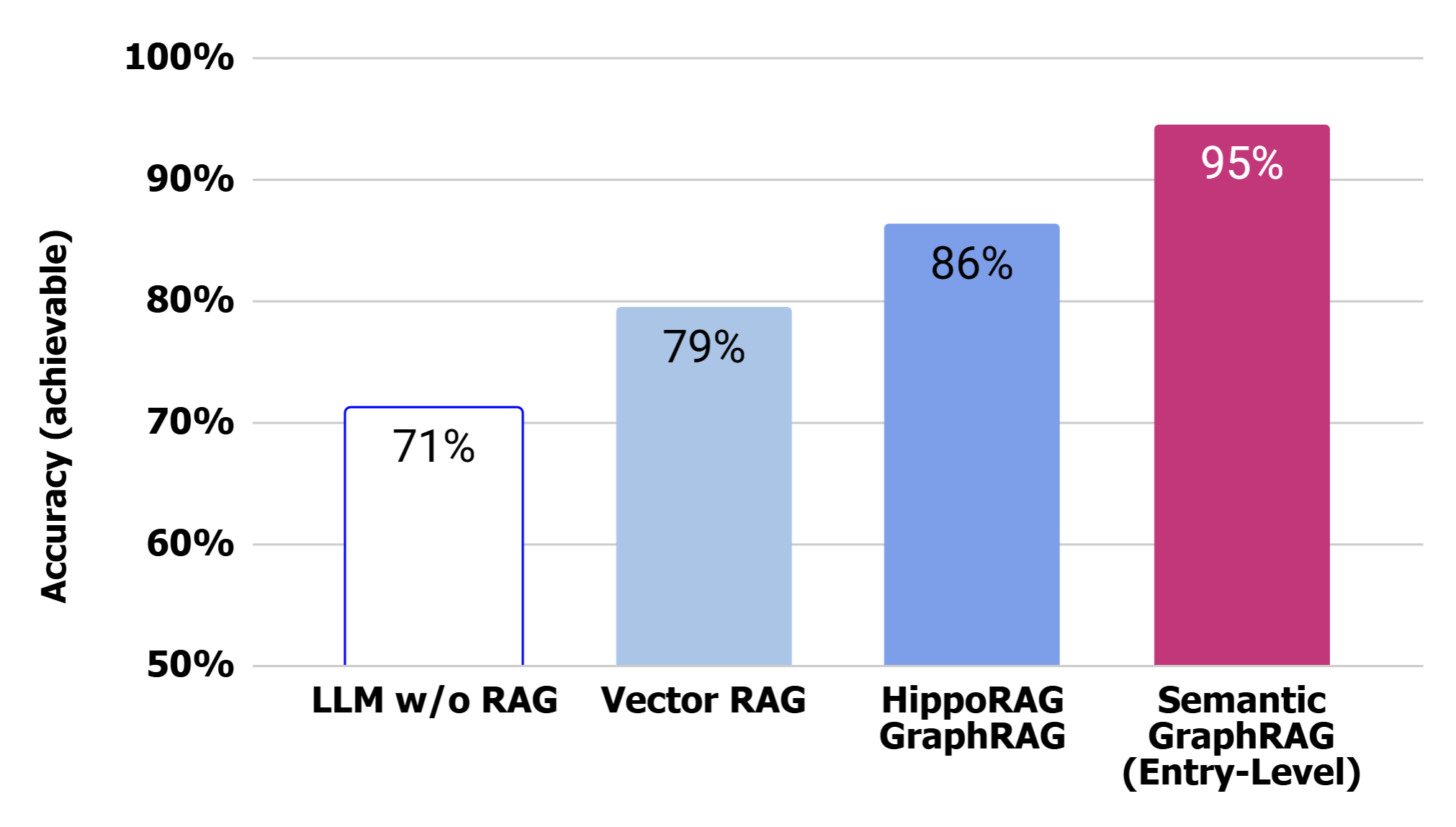
In this experiment our approach answered, on average, 69 of the 73 answerable questions correctly giving it a consistent advantage over HippoRAG.
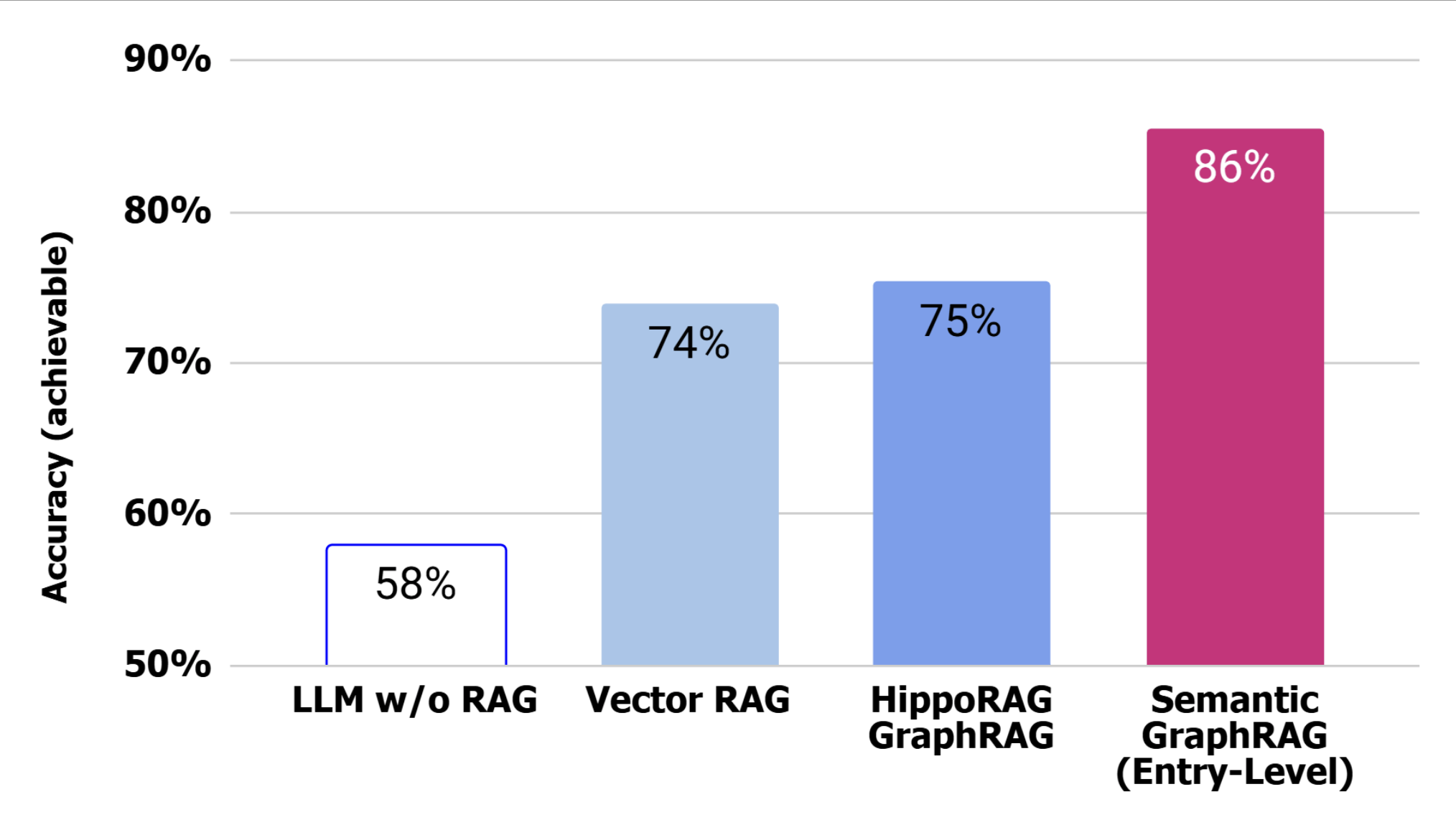
Performance on multi-hop questions
When testing across the full spectrum of available question complexity, the distinction between approaches grows clearer and Semantic GraphRAG demonstrates superior resilience. While Vector RAG and HippoRAG plateau near 75%, Semantic GraphRAG increases its dominant lead to 86%. This suggests that as reasoning chains get longer, the structured “highway” provided by the knowledge graph becomes increasingly critical for maintaining the trail of evidence.
In a nutshell
People don’t have time to browse, interpret, or reconcile conflicting sources. They need to pull answers, not documents, and they need to be able to set the context themselves. That said, content operations are to be centred around designing content for retrieval, not publication. They also need to be done with a view to capturing meaning in an explicit way before worrying about format. Last but not least we should be treating definitions and other cornerstone content chunks as first-class content assets.
In practice of the 69 answerable questions here, Vector RAG and HippoRAG answer 51-52 questions on average while Semantic GraphRAG averages 59.
Insights
Our deep dive into the MuSiQue dataset revealed a significant noise floor: many questions in the benchmark itself are flawed or ambiguous. In fact, across a variety of question samples, we established that about a third of the questions are not answerable — usually the expected answers are wrong or impossible to derive. An example of the latter is: “What is the administrative territorial entity that contains the location of Eric Marcus?”. The expected answer in the dataset is: “KUAT-TV 6”, which is a TV station, not an administrative territorial entity. An example of the former is: “In which country was the tournament held?”, which makes no sense without specifying which tournament the question is about.
However, benchmarks like MuSiQue fail to capture the true “power” of Semantic GraphRAG implemented via natural language querying (NLQ),— Aggregation. Standard RAG and GraphRAG systems are retrieval engines, not calculation engines. If you ask, “How many genes are associated with ALS?” or “Which gene is linked to the highest number of Alzheimer’s symptoms?“, standard systems fail. They attempt to retrieve text chunks and rely on the LLM to count. LLMs are notoriously poor at counting and the required context often exceeds token limits.
Semantic GraphRAG solves this deterministically. It doesn’t ask the LLM to count. It generates a SPARQL query (for example, SELECT COUNT(?gene)...). The result is a single, perfectly accurate number returned instantly. This ability to switch between “reading” (RAG) and “calculating” (SPARQL) is a paradigm shift for complex data analysis. This capability is referred to as NLQ, where natural language queries are converted to queries to a database engine.
Further improvements
We have some ideas for further improvements that can go in the following directions:
- The Q&A pairs of MuSiQue are designed to be answered via document chunks, without NLQ. We are developing a new benchmark designed specifically to test these capabilities. We aim to move beyond simple retrieval metrics and demonstrate what is possible when you treat your data as a true knowledge graph.
- Semantic GraphRAG can be improved further, using more advanced ontology and entity linking techniques. One direction would be to experiment using an existing ontology, for example, Schema.ORG or the ontology of Wikidata. This will save processing time (no need to generate an ontology). It will also make text-to-SPARQL generation faster and cheaper, because there will be no need to pass the ontology in the prompt – all major LLMs do know these popular ontologies.
- Personalized PageRank can be implemented directly in Graphwise GraphDB, which will void the need for a separate associative graph, stored in a separate engine.
Conclusion
By fusing the neurobiological inspiration of HippoRAG with the rigid structure of ontologies and semantic knowledge graphs, we have created a system that offers the best of both worlds. We retain the associative, “human-like” memory retrieval of HippoRAG, while injecting the logical precision required for multi-hop reasoning and complex aggregations.
The results are clear: structure matters. When you give an LLM a map (the ontology) and structured data (the knowledge graph) rather than just a pile of documents, it doesn’t just retrieve better — it reasons better.

Details
What is GraphRAG?
GraphRAG includes a graph database as a source of the contextual information sent to the LLM. Providing the LLM with textual chunks extracted from larger sized documents can lack the necessary context, factual correctness and language accuracy for the LLM to understand the received chunks in depth.
Learn moreRecommended Content

GeoAI: How GraphRAG Unlocks Complex Geospatial Knowledge
Read about how LLMs struggle with spatial queries, but connecting them to structured geographic knowledge graphs through GraphRAG improves accuracy.
Read more
Bring Your Enterprise Information Security Management System with GraphRAG to the Next Level
Read abou how GraphRAG systems enhance enterprise information security management by using knowledge graphs
Read more
GraphDB 11.1: Talk to Your Graph Using Any LLM
Read about how GraphDB 11.1’s chatbot tool helps you quickly setup and evaluate Graph RAG using different LLMs
Read moreFAQ
Any Questions? Look Here
HippoRAG (Hippocampal Retrieval-Augmented Generation) is a GraphRAG framework inspired by the neurobiological Hippocampal Indexing Theory, which mimics how the human brain indexes and retrieves associative memories. It operates through a two-phase process: first, an offline Indexing phase where an LLM extracts entities from a document corpus to construct a schemaless knowledge graph based on co-occurrence and semantic similarity. And second, an online retrieval phase that simulates neural activation. During retrieval, the system identifies initial query-relevant entities through vector search and then employs Personalized PageRank to traverse the graph, enabling it to perform complex multi-hop reasoning and find relevant information across disparate documents that lack direct textual overlap.
In production environments, the primary limitation of vanilla HippoRAG is its reliance on a schemaless graph built through simple co-occurrence or open information extraction, which lacks a formal semantic backbone and a consistent "world view." This associative approach often results in a performance plateau during complex multi-hop reasoning tasks, as it lacks the structured "highways" provided by formal ontologies to maintain a reliable trail of evidence across distant documents. Furthermore, because it depends heavily on semantic similarity for relationship traversal and lacks standardized schemas, it can struggle with data consistency and precision in domain-specific applications, making it less robust for enterprise-grade decision-making compared to semantically-augmented GraphRAG systems.
Semantic GraphRAG is an advanced retrieval-augmented generation approach that integrates Large Language Models (LLMs) with Semantic Knowledge Graphs governed by a structured semantic layer (taxonomies and ontologies), rather than relying solely on flat vector embeddings or schemaless graphs. While standard GraphRAG typically utilizes schemaless, associative graphs to capture literal entity relationships extracted from text, Semantic GraphRAG uses a formal knowledge model to provide explicit meaning, hierarchical context (e.g., broader and narrower concepts), and domain-specific rules. This differentiation allows Semantic GraphRAG to perform semantic query expansion and provide superior factual grounding and traceability, significantly reducing hallucinations by anchoring the AI’s reasoning in a verified, governed source of truth.
Semantic GraphRAG overcomes the limitations of HippoRAG and other GraphRAG solutions by replacing loose, schemaless graph constructions with a structured “semantic backbone” consisting of formal ontologies and a knowledge graph. While standard HippoRAG relies on simple co-occurrence or open information extraction — which can result in noisy, probability-based connections — Semantic GraphRAG introduces explicit, logic-based relationships that enable more precise multi-hop reasoning. By integrating deterministic tools like SPARQL queries alongside HippoRAG’s Personalized PageRank algorithm, it transforms retrieval from a purely associative process into a reasoning engine, significantly reducing inaccuracies and hallucinations while improving performance on complex, multi-hop question-answering benchmarks.