
Target Discovery – The Underlying Knowledge Graph Solution
AI-powered solution for intelligent target identification and selection helping companies to:
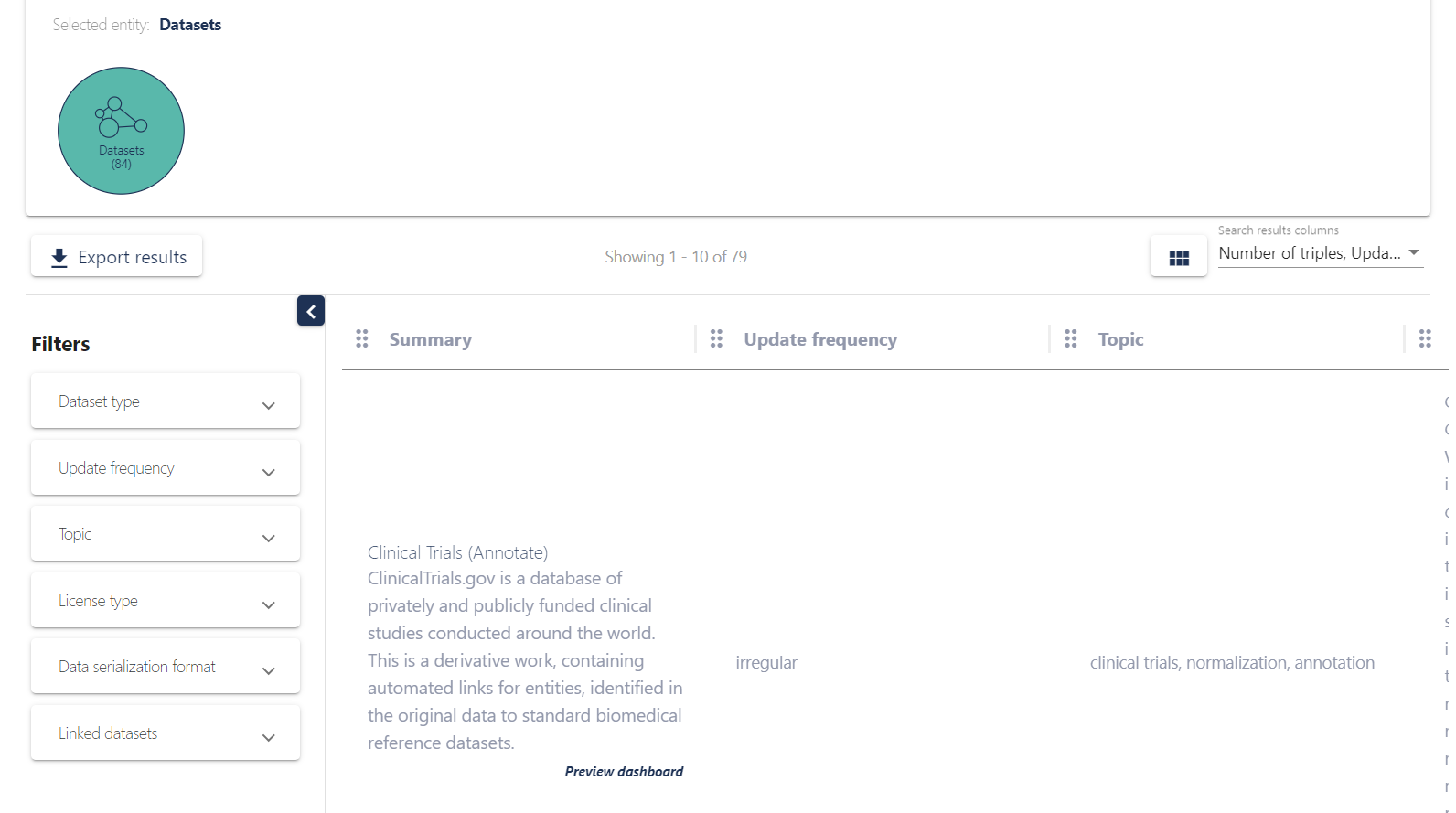
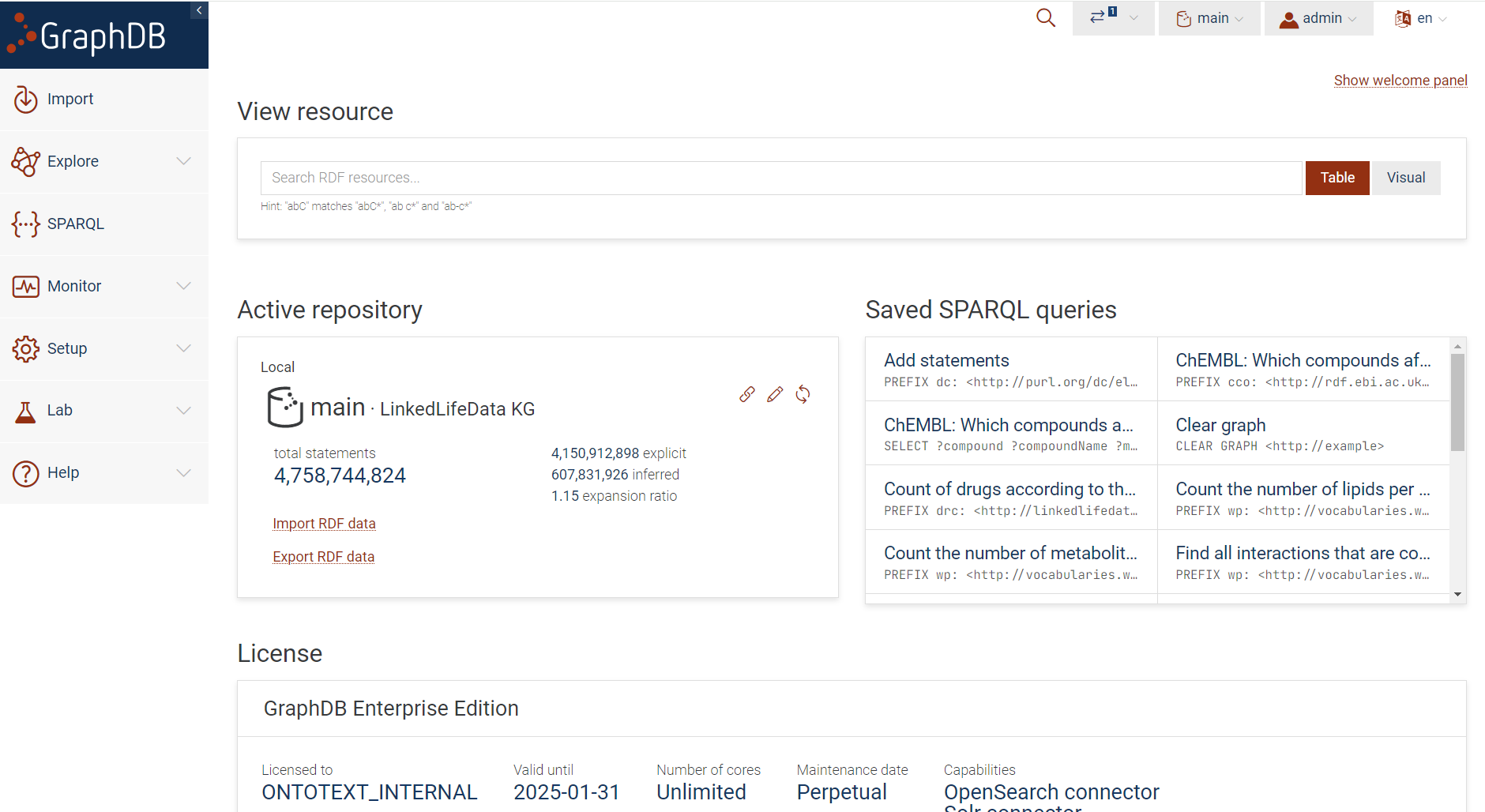
- Accelerate drug discovery & clinical research by centralizing biomedical knowledge to discover new hypotheses and facilitate data-driven decision-making
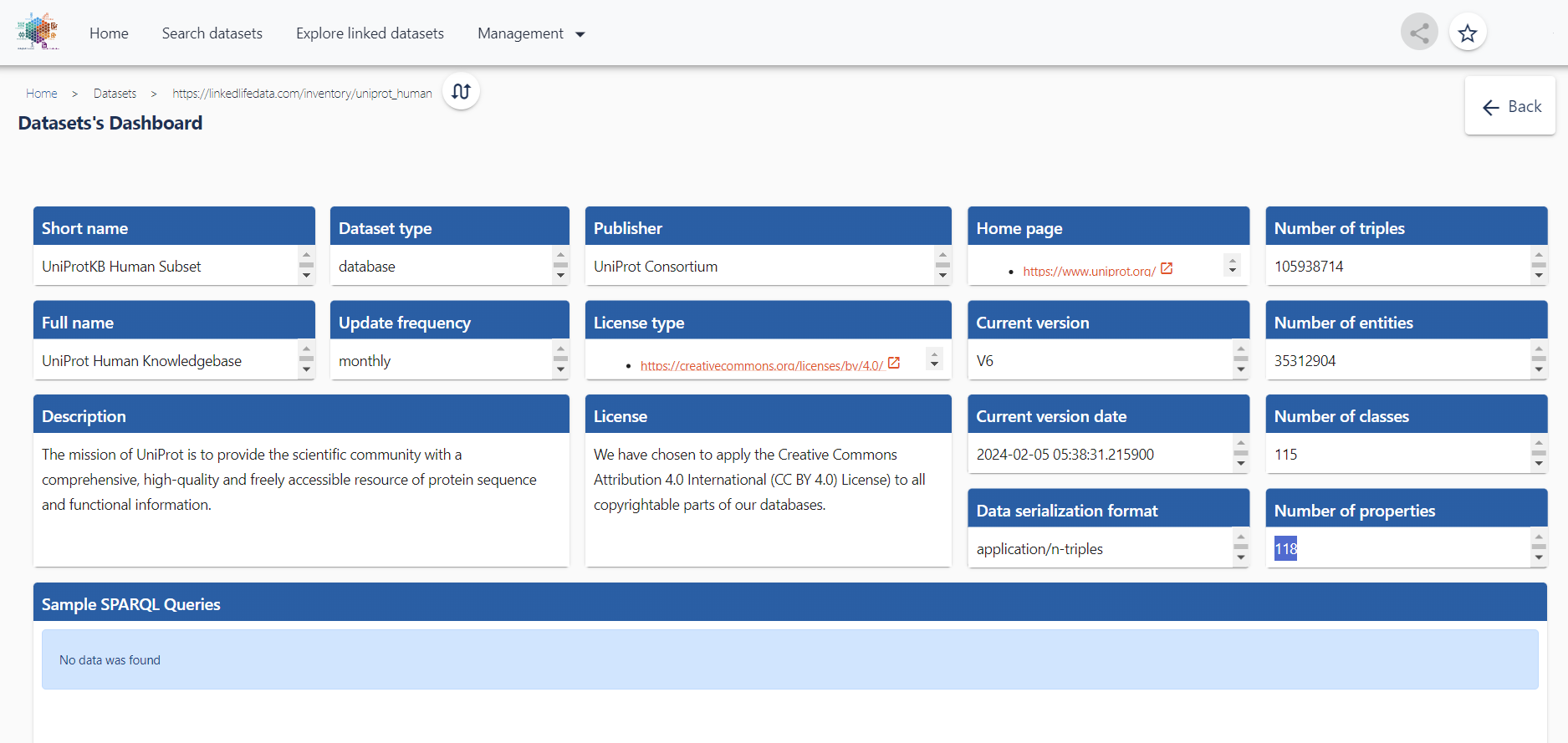
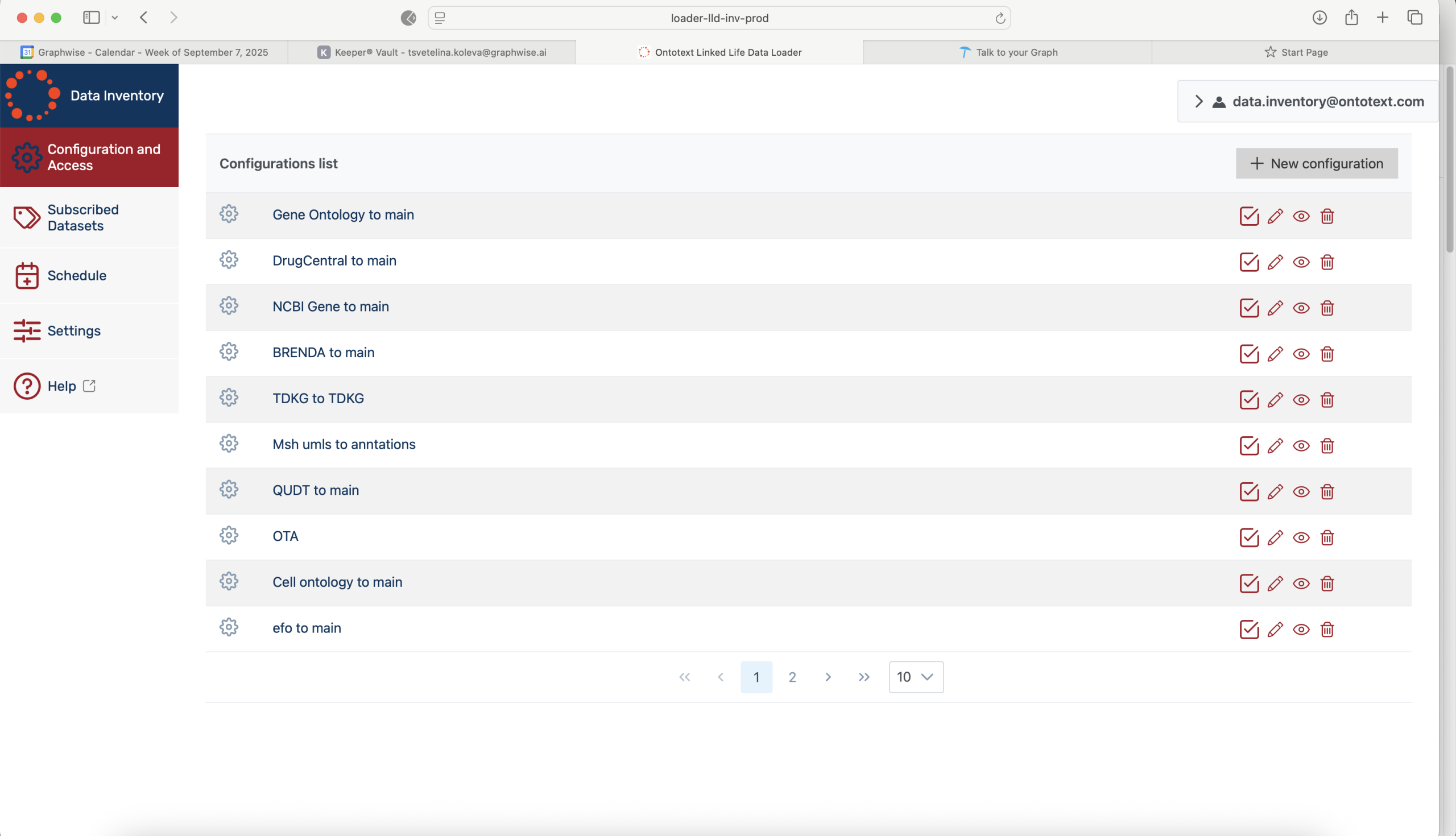
- Select the best targets by using customizable analytical methods on various data sources with transparent provenance
- Reduce the cost and time for validation through intelligent ranking and prioritization of targets and hits
10x
Faster Drug Discovery
5x
Lower Cost & Time for Target Validation



